TCP的经典异常问题无非就是丢包和连接中断,在这里我打算与各位聊一聊TCP的RST到底是什么?现网中的RST问题有哪些模样?我们如何去应对、解决?本文将从RST原理、排查手段、现网痛难点案例三个板块自上而下带给读者一套完整的分析。

一、背景
最近一年的时间里,现网碰到RST问题屡屡出现,一旦TCP连接中收到了RST包,大概率会导致连接中止或用户异常。如何正确解决RST异常是较为棘手的问题。
本文关注的不是细节,而是方法论,也确实方法更为重要。笔者始终相信,一百个人眼中的哈姆雷特最终还是一个具体的人物形象,一百个RST异常最终也会是一个简短的小问题。
二、原理
首先,我们需要确定的RST问题一定就是问题吗?如果RST发生了你会如何去解决?读者可以尝试问下自己并解答这个问题,这里”停顿、停顿、停顿“来给大家一点时间思考,好了,时间到,我们继续往下看。
RST分为两种,一种是active rst,另一种是passive rst。前者多半是指的符合预期的reset行为,此种情况多半是属于机器自己主动触发,更具有先前意识,且和协议栈本身的细节关联性不强;后者多半是指的机器也不清楚后面会发生什么,走一步看一步,如果不符合协议栈的if-else实现的RFC中条条杠杠的规则的情况下,那就只能reset重置了。
这里贴上RFC 793最经典的最初对RST包的解释:

1.active rst
那具体什么是active rst?如果从tcpdump抓包上来看表现就是(如下图)RST的报文中含有了一串Ack标识。
这个对应的内核代码为(如果感兴趣):
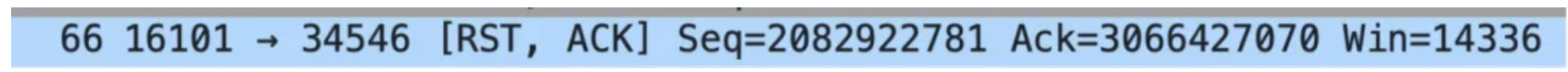
通常发生active rst的有几种情况:

主动方调用close()的时候,上层却没有取走完数据;这个属于上层user自己犯下的错。
主动方调用close()的时候,setsockopt设置了linger;这个标识代表我既然设置了这个,那close就赶快结束吧。
主动方调用close()的时候,发现全局的tcp可用的内存不够了(这个可以sysctl调整tcp mem第三个参数),或,发现已经有太多的orphans了,这时候系统就是摆烂的意思:我也没辙了”,那就只能干脆点长痛不如短痛,结束吧。这个案例可以搜索(dmesg日志)“too many orphaned sockets”或“out of memory -- consider tuning tcp_mem”,匹配其中一个就容易中rst。
注:这里省略其他使用diag相关(如ss命令)的RST问题。上述三类是主要的active rst问题的情况。
2.passive rst
现在继续说说另一种passive rst吧。如果从抓包上来看表现就是(如下图)rst的报文中无ack标识,而且RST的seq等于它否定的报文的ack号(红色框的rst否定的黄色框的ack),当然还有另一种极小概率出现的特殊情况的表现我这里不贴出来了,它的表现形式就是RST的Ack号为1。

这个对应的内核代码为(如果感兴趣):

通常发生passive rst的有哪些情况呢?这个远比active rst更复杂,场景更多。具体的需要看TCP的收、发的协议,文字的描述可以参考rfc 793即可。
三、工具
我们针对线上这么多的rst如何去分析呢?首先tcpdump的抓捕是一定需要的,这个可以在整体流程上给我们缩小排查范围,其次是,必须要手写抓捕异常调用rst的点,文末我会分享一些源码出来供参考。
那如何抓调用RST的点?这里只提供下思路。
1.active rst
使用bpf*相关的工具抓捕tcp_send_active_reset()函数并打印堆栈即可,通过crash现场机器并输入“dis -l [addr]”可以得到具体的函数位置,比对源码就可以得知了。
可以使用bpftrace进行快速抓捕:

堆栈结果如图:
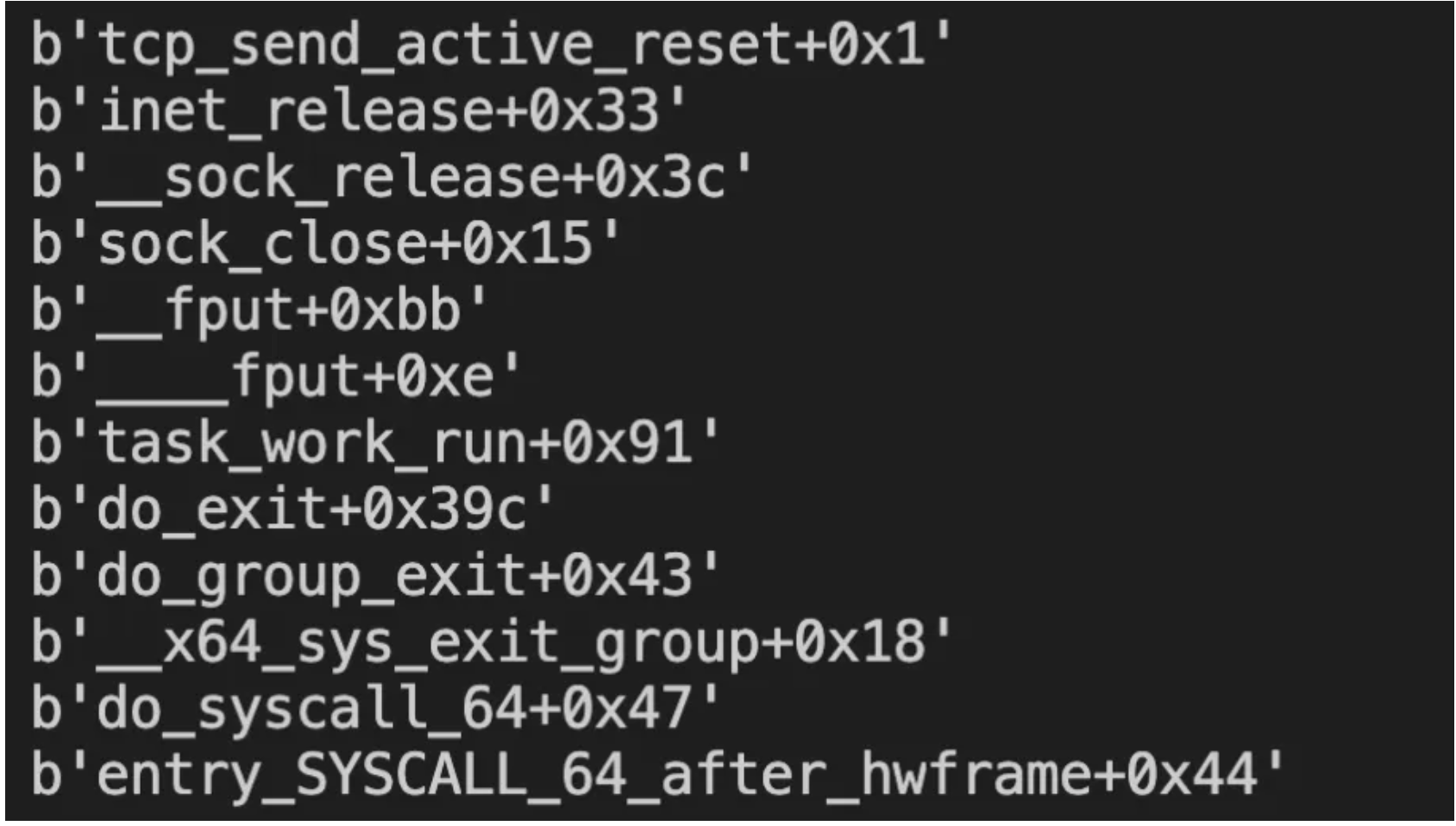
我们可以根据堆栈信息推算上下文。
2.passive rst
使用bpf*相关的工具抓捕抓捕tcp_v4_send_reset()和其他若干小的地方即可,原理同上。

效果如图:
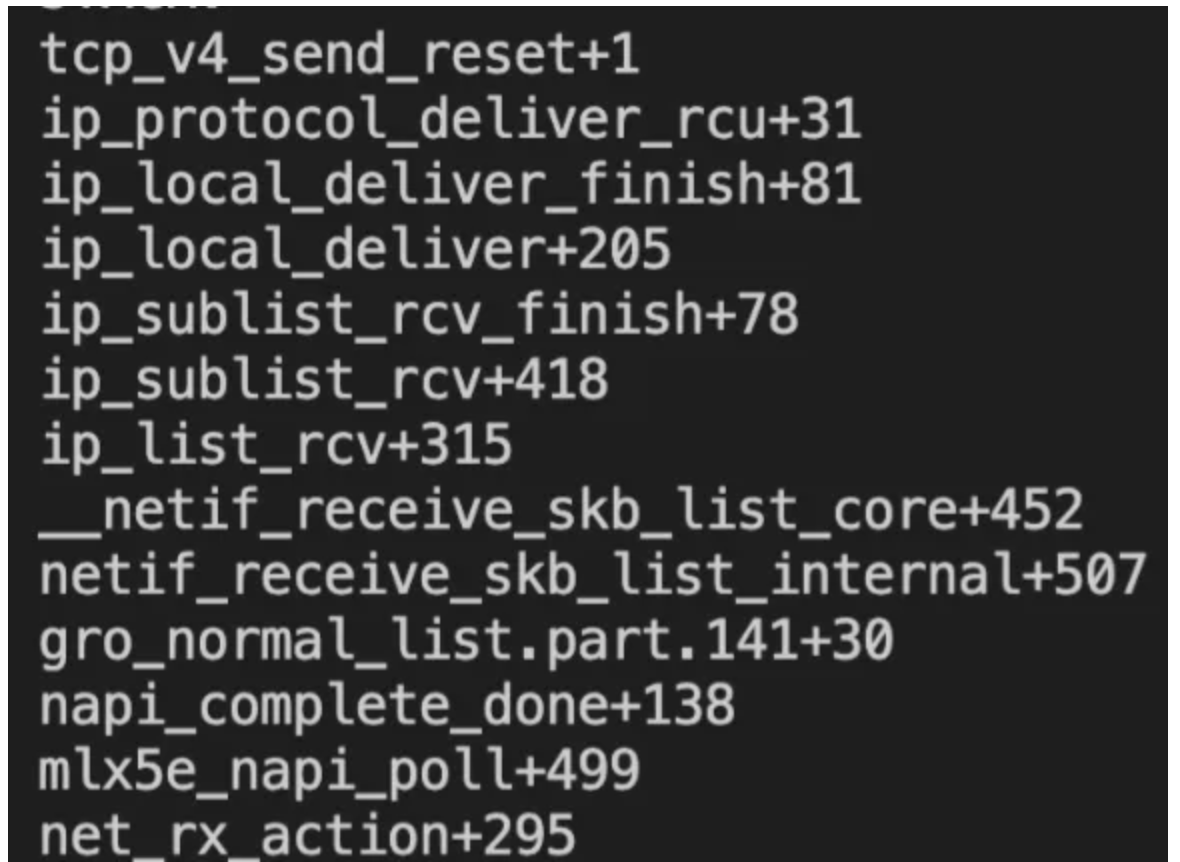
当然,无论那种,我们抓到了堆栈后依然需要输出很多的关于skb和sk的信息,这个读者自行考虑即可。再补充一些抓捕小技巧,如果现网机器的rst数量较多时候,尽量使用匹配固定的ip+port方式或其它关键字来减少打印输出,否则会消耗资源过多!
注:切记不能去抓捕reset tracepoint(具体函数:trace_tcp_send_reset()),这个tracepoint实现是有问题的,这个问题已经在社区内核中存在了7年之久!目前我正在修复中。
四、案例分析
本章节我将用现网实际碰到的三个”离谱“而且让我非常”咬牙切齿“的case作为案例分析,当时在查这些问题的时候我提前告知业务”不保证有能力解决 :(“,不过最终还是用时间磨赢了bug。那么,这里让各位读者可以看下极为复杂的RST案例到底长成什么样?对内核不感兴趣的同学可以不用纠结具体的细节,只需要知道一个过程即可;对内核感兴趣的同学不妨可以一起构造RST然后自己再抓取的试试。
第一个案例:小试牛刀—— close阶段RST
背景:这是线上出现概率/次数较多的一种类型的RST,业务总是抱怨为何我的连接莫名其妙的又没了。
我们先使用网络异常检测中最常用的工具:tcpdump。如下抓包的图片再结合前文对RST的两种分类(active && passive)可知,这是active rst。
好,既然知道了是active rst,我们就针对性的在线上对关键函数抓捕,如下:
通过crash命令找到了对应的源码,如下:
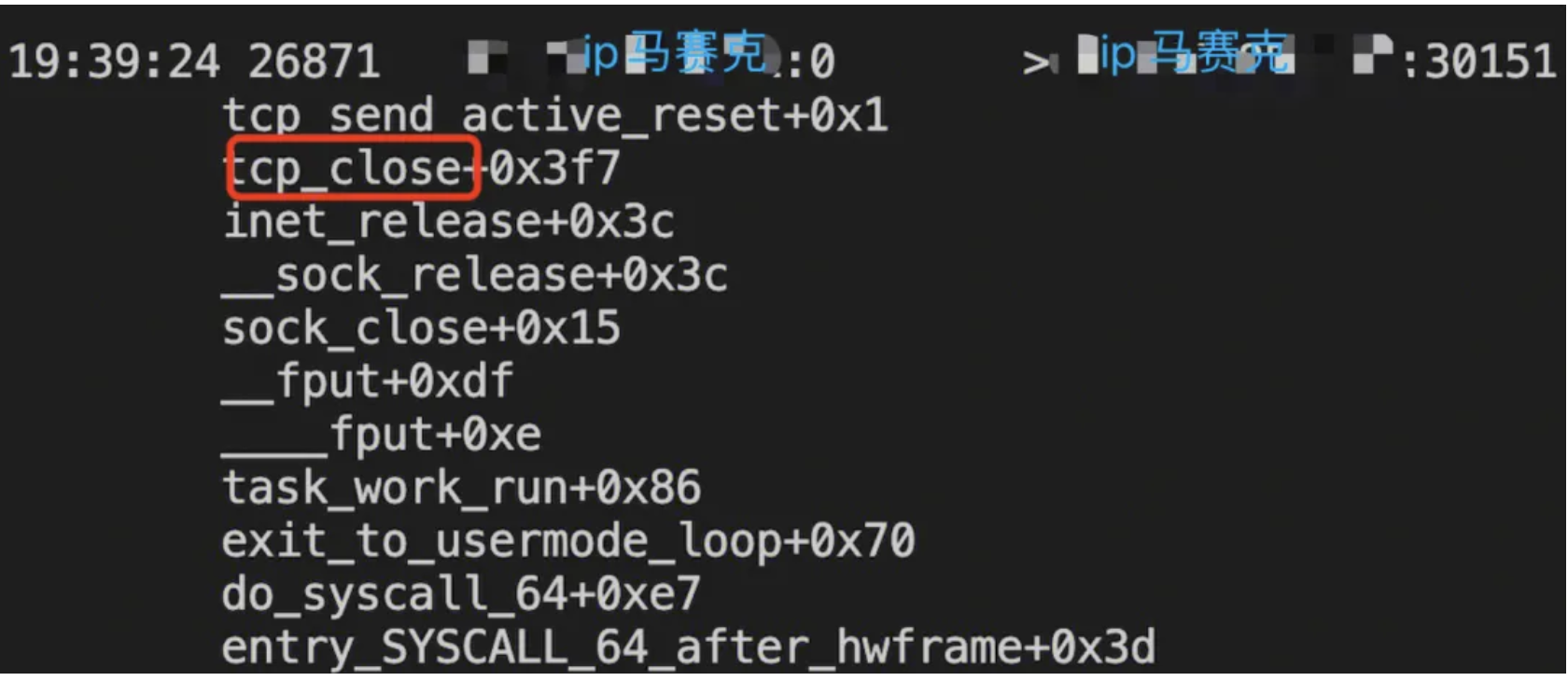
这时候便知是用户设置了linger,主动预期内的行为触发的rst,所以本例就解决了。不过插曲是,用户并不认为他设置了linger,这个怎么办?那就再抓一次sk->sk_lingertime值就好咯,如下:
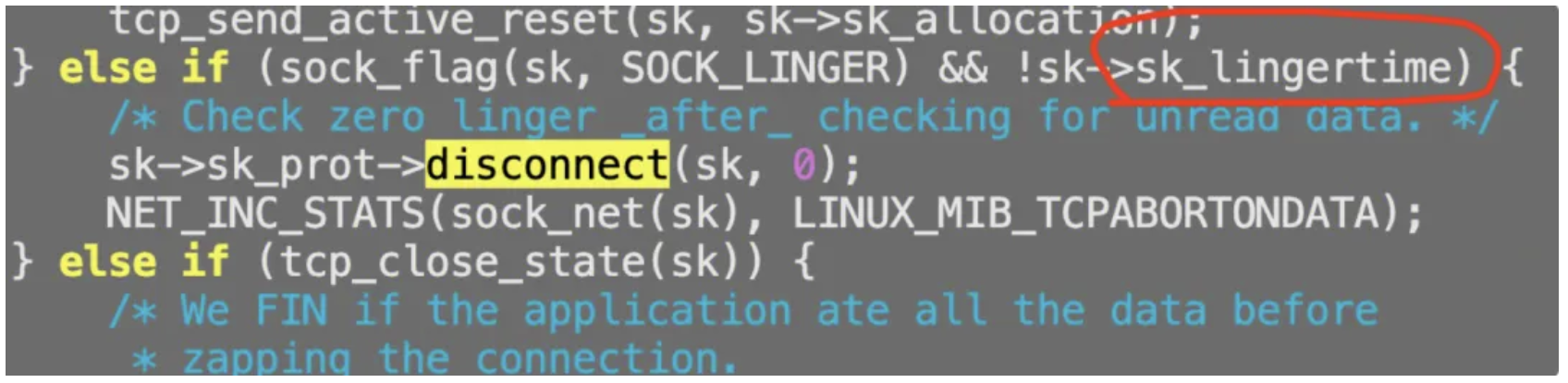
计算:socket的flag是784,第5位(从右往左)是1,这个是SO_LINGER位置位成功,但是同时linger_time为0。这个条件默认(符合预期)触发:上层用户退出时候,不走四次挥手,直接RST结束。
结论:linger的默认机制触发了加速结束TCP连接从而RST报文发出。
第二个案例:TCP 两个bug —— 握手与挥手的RS
背景:某重点业务报告他们的某重点用户出现了莫名其妙的RST问题,而且每一次都是出现在三次握手阶段,复现概率约为——”按请求数来算的话差不多百万级别分之1的概率,概率极低“(这是来自业务的原话)。
这里需要剧透一点的是,后文提到的两个场景下的rst的bug,都是由于相同的race condition导致的。rcu保护关注的是reader&writer的安全性(不会踩错地址),而不保护数据的实时性,这个很重要。所以当rcu与hashtable结合的时候,对整个表的增删和读如何保证数据的绝对的同步显得很重要!
(1) 握手阶段的TCP bug

问题的表象是,三次握手完毕后client端给server端发送了数据,结果server端却发送了rst拒绝了。
分析:注意看上图最左边的第4和5这两行的时间间隔非常短,只有11微妙,11微妙是什么概念?查一次tcp socket的hash表可能都是几十微妙,这点时间完全可能会停顿在一个函数上。
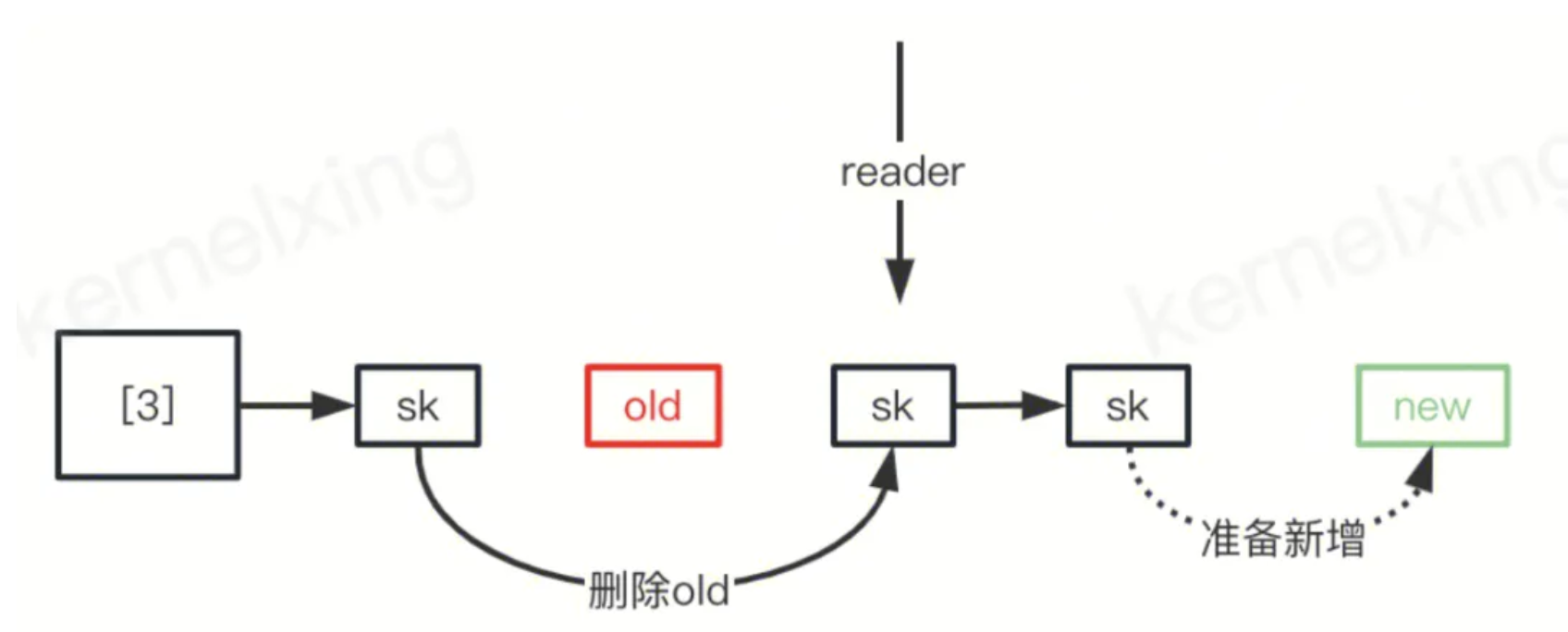
当server端看到第三行的ack的时候几乎同时也看到了第四行的数据,详细来说,这时候server端在握手最后一个环节,会在socket的hash表中删除一个老的socket(我们叫req sk),再插入一个新的socket(我们叫full sk),在删除和插入之间的这短暂的几微妙发生的时候,server收第行的数据的时候需要去到这个hash表中寻找(根据五元组)对应的socket来接受这个报文,结果在这个空档期间没有匹配到应该找到的socket,这时候没办法只能把当时上层最初监听的listener拿出来接收,这样就出现了错误,违背了协议栈的基本的设计:对于listener socket接收到了数据包,那么这个数据包是非预期的,应该发送RST!

对应上图的cpu0就是server的第四行的读者,cpu1就是写者,对于cpu0而言,读到的数据可能是三种情况:1)读到老的sk,2)读到新的sk,3)谁也读不到,前两个都是可以接收,但是最后一个就是bug了——我们必须要找到两者之一!如下就是一种场景,无法正确找到new或者old。
那如何修复这个问题?在排查完整个握手规则后,发现只需要先插入新的sk到hash桶的尾部,再删除老的sk即可,这样就会有几种情况:1)两个同时都在,一定能匹配到其中一个,2)匹配到新的。如下图,无论reader在哪里都能保证可以读到一个。如下是正确的:
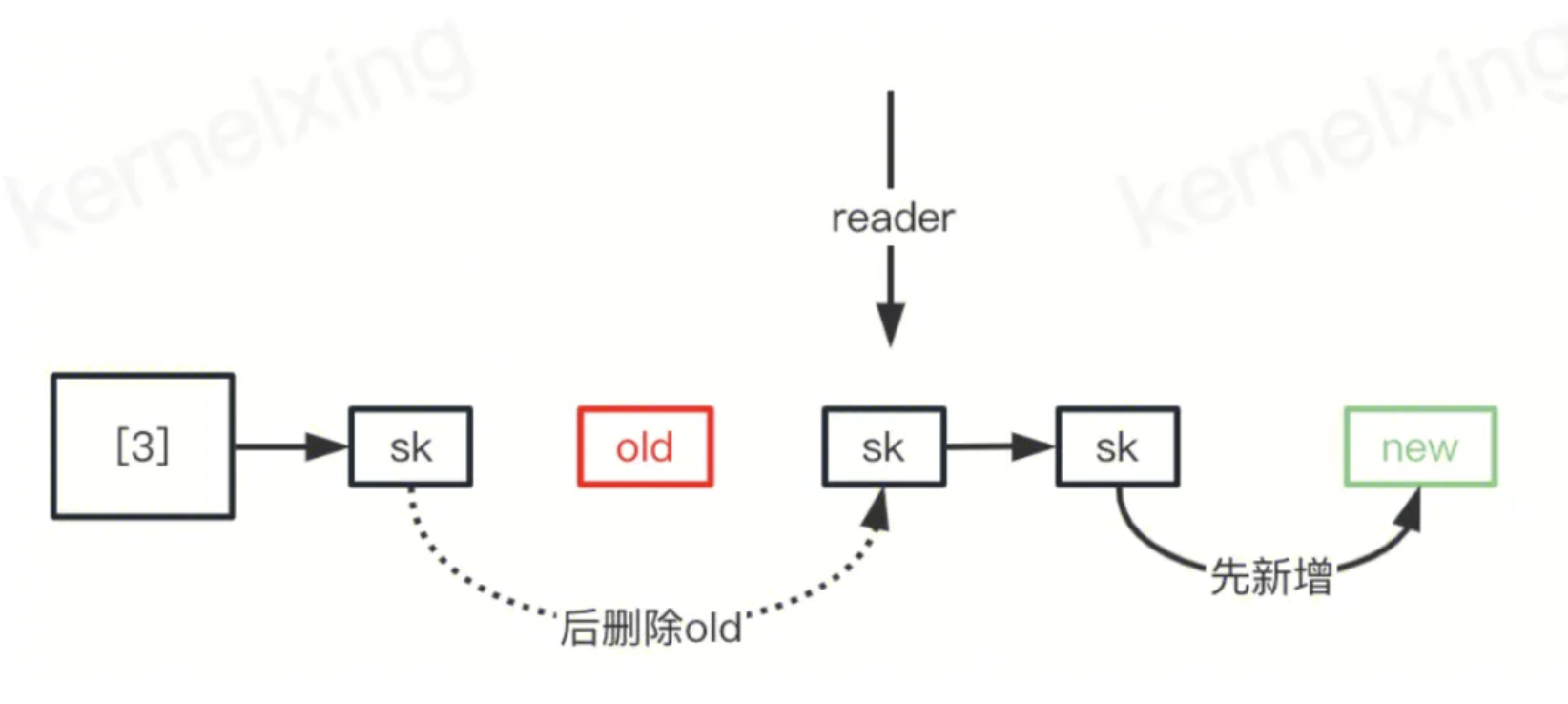
结论:第3行(client给server发生了握手最后一次ack)和第4行(client端给server发送了第一组数据)出现的并发问题。
(2) 挥手阶段的bug

这个问题根因同上:rcu+hash表的使用问题,在挥手阶段发起close()的一方竞争的乱序的收到了一个ack和一个fin ack触发,导致socket在最后接收fin ack时候没有匹配到任何一个socket,又只能拿出最初监听的listener来收包的时候,这时候出现了错误。但是这个原始代码中,是先插入新的sk再删除了老的sk,乍一听没有任何问题,但是实际上插入新的sk出现了问题,源码中插入到头部,这里需要插入到尾部才行!出现问题的情景如下图。
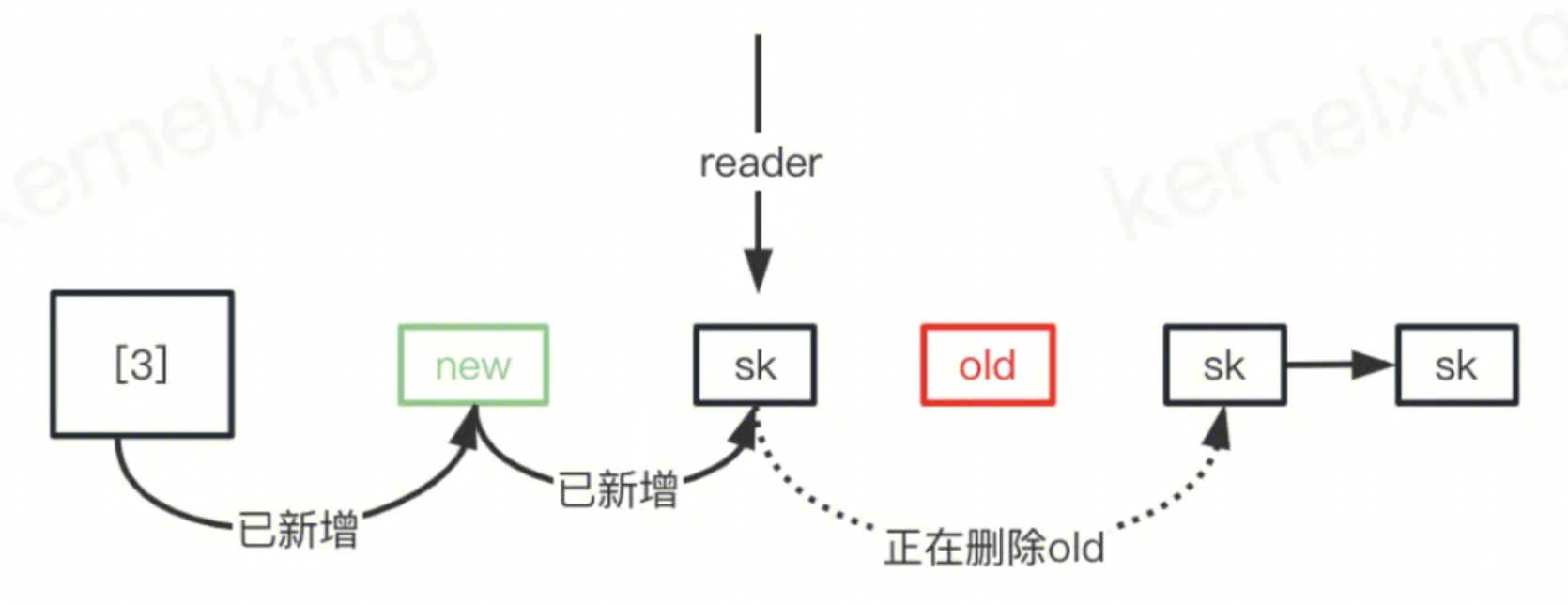
结论:这个是原生内核长达十多年的一个实现上的BUG,即为了性能考虑使用的RCU机制,由此必然引入的不准确性导致并发的问题,我定位并分析出这个问题的并发的根因,由此提交了一份bugfix patch到社区被接收,链接:https://git.kernel.org/pub/scm/linux/kernel/git/netdev/net.git/commit/?id=3f4ca5fafc08881d7a57daa20449d171f2887043
第三个案例:netfilter两个bug —— 数据传输RST
背景:用户报告有两个痛点问题:偶发性出现1)根本无法完成三次握手连接,2)在传输数据的阶段突然被RST异常中止。
分析:我们很容易的通过TCP的设计推测到这种情况一定不是正常的、符合预期的行为。我抓取了passive rst后发现原因是TCP层无法通过收到的skb包寻找到对应的socket,要知道socket是最核心的TCP连接通信的基站,它保存了TCP应有的信息(wscale、seq、buf等等),如果skb无法找到socket,那么就像小时候的故事小蝌蚪找妈妈但是找不到回家的路一样。
那为什么会出现找不到socket?
经过排查发现线上配置了DNAT规则,如下例子,凡是到达server端的1111端口或1112端口的都被转发到80端口接收。

DNAT+netfilter的流程是什么样?
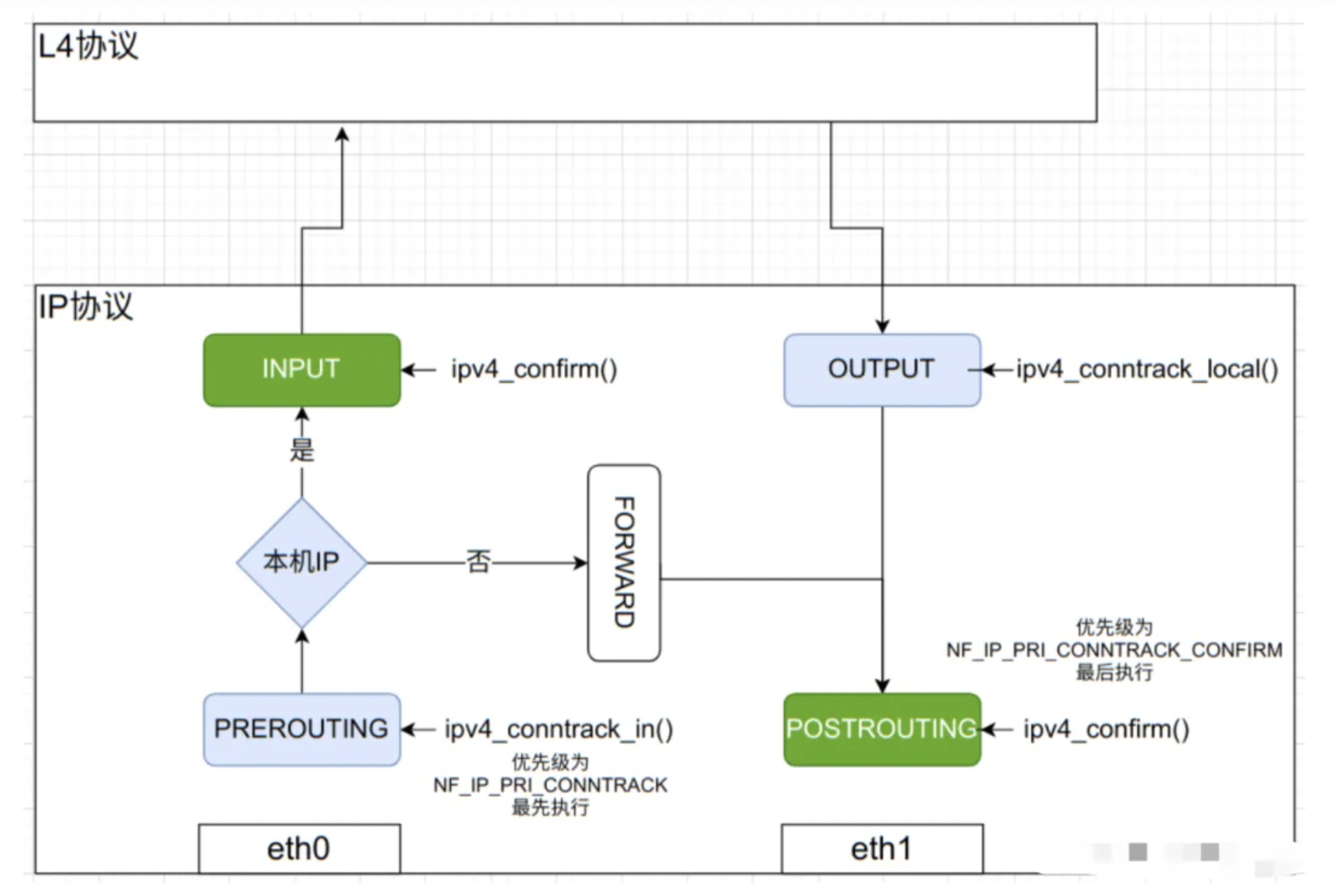
那么,有了DNAT之后,凡是进入到server端的A port会被直接转发到B port,最后TCP完成接收。完整的逻辑是这样:DNAT的端口映射在ip层收包时候先进入prerouting流程,修改skb的dst_ip:dst_port为真正的最后映射的信息,而后由ip early demux机制针对skb中的原始信息src_ip:src_port(也就是A port)修改为dst_ip:dst_port(也就是使用B port),由此4元组hash选择一个sk,继而成功由TCP接收才对。
(1) 两条流冲突触发的bug
如下,如果这时候有两条流量想要TCP建连,二者都是由同一个client端相同的ip和port发起连接,这时候第1条连接首先发起握手那么肯定可以顺利进行,而当第2条连接发起的时候抵达到server端的1112端口最终被转化为80端口,但是根据80端口可以发现我们已经建立了连接,所以第2条流三次握手直接失败。

我需要补充的信息是:NAT转化port分为两次,对于上述第二条流,第一次转化1112为80,第二次转化12345为1112,最终此流变为[saddr:1112 -> daddr:80]
第一条流:skb对应的sk是[saddr:12345 -> daddr:80],这个没有NAT参与。
第二条流:skb在ip层这时候NAT刚完成第一次port(修改dport 1112为dport 80),然后进入了early demux机制,此时的4元组是[saddr:12345 -> daddr:80],所以这时候匹配上了第一条流的sk,但是系统并不知情有问题了,紧接着NAT第二次改变skb的port,变为[saddr:1112 -> daddr:80],这个也是后续TCP层延续使用的,虽然这个4元组信息是对的,但是已经没有用了,因为early demux阶段已经获取、保存socket了。
注:内核修复后,对于第二条流就是放弃early demux阶段选择的4元组,而是安心等待NAT完成两轮port的转化之后,使用[saddr:1112 -> daddr:80]来匹配socket,这时候发现没有对应的socket,就找到了listener socket,从而完成三次连接。
结论:这个是early demux+DNAT的bug,它未能解决冲突问题,导致了异常RST的发生。
(2) 特殊skb触发的bug
注:在这个场景里面多了一个中间的gateway。
在本例中,我发现依然是熟知的一幕,skb无法lookup寻找到对应的socket,此时我们要相信一定不会lookup算法出错,因为此算法仅仅是做简单的4元组的hash计算与匹配。所以追溯异常的skb和socket的四元组信息是头等事情,经过对比果然发现skb的端口信息未能成功被iptables转化为B port,所以使用了含有A port的四元组信息去找socket,而socket当初的建立是使用了B port,所以skb与sk的相遇就这么擦身而过了。
(对内核细节不感兴趣的同学可以跳过后面大段)
那么为什么会DNAT无法转化?
我们先看下,异常未被转化的skb和应当能接收的socket的4元组信息:

client->gw->server的流程中,由于gw侧发送了一些unknown skb再加上client端发送了一些out-of-window的包,导致进入到server的netfilter阶段会被识别出来INVALID异常,这个异常被识别后直接清除netfilter保持的该有的流信息,继而异常的skb抵达DNAT阶段后无法转化端口(因为判断转化的流信息没有了),最终skb无法成功转化port端口号。
这个是netfilter+DNAT的设计上的bug,我认为:无论是否有netfilter,都不应当是TCP的行为被改变,所以如果netfilter识别到了问题所在,1)要么忽视,直接传给TCP,交给TCP处理,2)要么丢弃,这样也能避免RST的发生。但是,就这么一个小小的细节上,我和社区的几个维护者拉锯战的battle了三百回合(链接:https://lore.kernel.org/all/20240311070550.7438-1-kerneljasonxing@gmail.com/),可惜虽然有一个维护者ACK了我的补丁,但是另外的维护者考虑netfilter不适合用于丢包功能,所以让用户去使用iptables --log功能、检测出invalid异常包、继而用iptables配置主动丢弃。就凭这点,我认为严重违背了user friendly的初衷,这些应该是default默认功能才对。此时的我虽然表面打不过,但是在内心世界里很显然我battle赢了...
结论:netfilter识别异常的skb未能成功保留DNAT信息,导致最后port端口不能成功被转化,从而触发了TCP的RST行为。
五、小结
RST问题并不可怕,只要思路理清楚,先判断类型,再抓取对应代码,继而翻出RFC协议,最后分析源码就能搞定,仅仅四步就可以了 :)
希望这篇文章对大家有用!

