4月10日,以“共创云网智联新时代·释放数实融合新动能”为主题的2024年云网智联大会在京举办。会上,中国电信集团科技委主任韦乐平从人工智能的三大要素和三层次模型、ChatGPT的技术核心与局限、大模型的发展、人工智能的基本挑战与极限四个方面,发表了分享与见解。

▲中国电信集团科技委主任 韦乐平
人工智能的三大要素和三层次模型
算力是AI的基础。芯片水平决定AI计算能力的物理上限,关键是GPU及其应用生态。目前,高端芯片制程,特别是GPU及其应用生态是我国AI发展的最大短板。
数据是AI的根本。数据要素是数字经济的核心生产要素和重要经济资源。数据的规模、质量和治理体系决定了AI应用的效果和质量。数据的可用数量和质量也是我国短板。
算法是AI的灵魂。算力离开算法只是一个巨大的高耗能电热器,基于深度学习的高效智能算法是发挥算力作用,规避低效蛮力计算的必然方向。
人工智能的三层次模型如下:
第一层次:任务模型(TSAI),即模型的应用。完成特定领域的特定任务,例如人脸识别,下棋等,属于应用层。
第二层次:领域模型,即行业模型。可完成多领域的诸多任务,例如普通教师,医生,律师等职业。特别是脸书的基础大模型LIama的意外泄漏和开源,大大降低了开发者门槛,只需要在基础大模型上根据具体任务做微调即可。从无意泄露到有意开源,大大推进了行业模型的发展。
第三层次:认知模型(AGI),即通用人工智能,能看、能听、能思考、能规划,实现真正类人的智能。但终究只是具备了丰富只是的书呆子,缺乏实践感悟,更没有人类特有的意识、感情和道德。估计还需要5年、10年、20年才能实现。
大(语言)模型的基本特征包括:大算力、大参数、大数据、大智能。
算力规模越大、模型参数越多、高质量数据越多,智能就越高,越能解决复杂的任务和推演出更高水平的结果。
行业模型,百亿至千亿参数,基础通用大模型,千亿至万亿参数。全球领先的基础通用大模型,则需数万亿至数十万亿级的参数。
一定的通用性起码具备领域型模型特点,能完成多领域的诸多任务,非单一任务。
当算力和模型参数足够大,训练到一定程度后,能够突然出现预料之外的某种能力,产生逻辑自洽的类人语言表达,这种能力会达到乃至超过人类某方面的智慧。
ChatGPT开创人工智能新时代
ChatGPT是OpenAI开发的聊天机器人程序,是AI驱动的自然语言处理工具,GPT-4版本不仅能聊天,而且已具备多模态能力和自主学习、自我进化能力,正成为一款智能决策和创作系统。
GPT-4不仅在语言,还在数学、编程、绘画、医学、法律等多领域表现出色。同时,其自主学习思考、自我更新进化能力也给人类带来难预测、不可控的深远影响。
GPT-4引入了知识和经验,但依然靠蛮力计算,遵循算力决定智力的路径,算力成本和功耗很高,对数据规模和数据质量要求很高,但时效性和通用性不强,推理能力还不够强,训练推理结果既难预测,也不可控,估计至少已具备10%的通用AI能力。
GPT-5将具有极强推理能力,估计将至少具备20%的通用AI能力。
ChatGPT的技术核心是引入基于人类反馈的强化学习(RLHF),使得模型训练和推理结果与人类常识、认知、需求、价值观对齐,还能自己创编新知识。
韦乐平用“大力出奇迹”来形容ChatGPT的技术局限。
蛮力计算无底洞,估计GPT-6可能需要10万张H100卡,耗电7百万度,加州电网也难支撑。算力尽头是能源,靠核聚变电厂。
海量的高质量语料库和高效算法训练才能使模型拟合真实世界,GPT-4模型参数已达到1.8万亿(超松鼠大脑),离人脑(100万亿)不太遥远,但仍有荒谬应答(幻觉),幸顿称其为“白痴天才”。
生成式AI尚处于期望膨胀期,潜力不可低估,也不应无限夸大,并不适用一切场景,多数场景有更多其他AI技术更适用。
当然,ChatGPT的潜在风险也不容忽视。
算法黑箱导致不可预测的信任危机和潜在风险,自主学习、自我进化能力给人类带来不可预测,难以控制的训练结果,甚至潜在的灾难。
高度拟人的训练结果强化了假信息的逼真度和传播速度,错误的训练结果会导致人类做出错误决策,引发社会混乱,导致信息安全和隐私泄露。
GPT无偿的学习和利用了大量传媒的内容而不付费,导致版权体系的崩塌。
预计有数以亿计普通白领工作被替代,可能造成社会动乱。
大模型的价值在应用。
最尖端领域具备高技术、高投入、高能耗、高风险。仅ChatGPT等5-6个基础大模型能够长期存活。
次尖端领域聚焦在行业大模型,它们层出不穷,成千上万,各领风骚。
泛在应用无穷无尽,是各类大模型真正体现价值和商业落地的地方。
与此同时,小模型的作用不容轻视。
大模型训练所需要的技术、算力、语料以及成本很高,却通而不专,在面向具体运行环境的适应性和经济性方面,往往小模型更加实用,省钱、省力、省时间。目前已经有多种小模型产品问世,技术角度看,有两大方向:
知识蒸馏:主要对大模型进行裁剪、优化,使训练好的模型的体积和尺寸更小、成本更低、更适合具体部署环境的实际需求。
微型机器学习(TinyML):旨在低于1mW功耗下(如纽扣电池)运行机器学习,解决成本和功率受限系统中完成机器学习任务,是物联网领域AI的主要方向之一。
大模型的发展对高质量网络连接的期待
为了支持越来越大的模型训练新需求,规避伴随而来的性能、处理时长和成本的挑战,GenAI需要最 佳联网技术的支撑,目前五种:
以太网:传统以太网难以支持大模型训练,但是基于强大以太网生态上的无损以太网,特别是超级以太网仍将是最重要的联网技术。
PCIe:可以为复杂的GenAI扩展距离、简化系统架构、减少功耗。
芯片光互联:相比芯片电互连,可以大幅提升计算集群的扩展性(超100T),功耗很低,物理尺寸也更小。
CXL:不仅可以继续用来增大服务器的内存规模,而且将越来越多的用来承担GenAI训练的加速器作用。
IB:目前是性能最 佳的成熟联网技术,但是封闭和价高,仍将维系在高端大模型训练时长的相当份额。
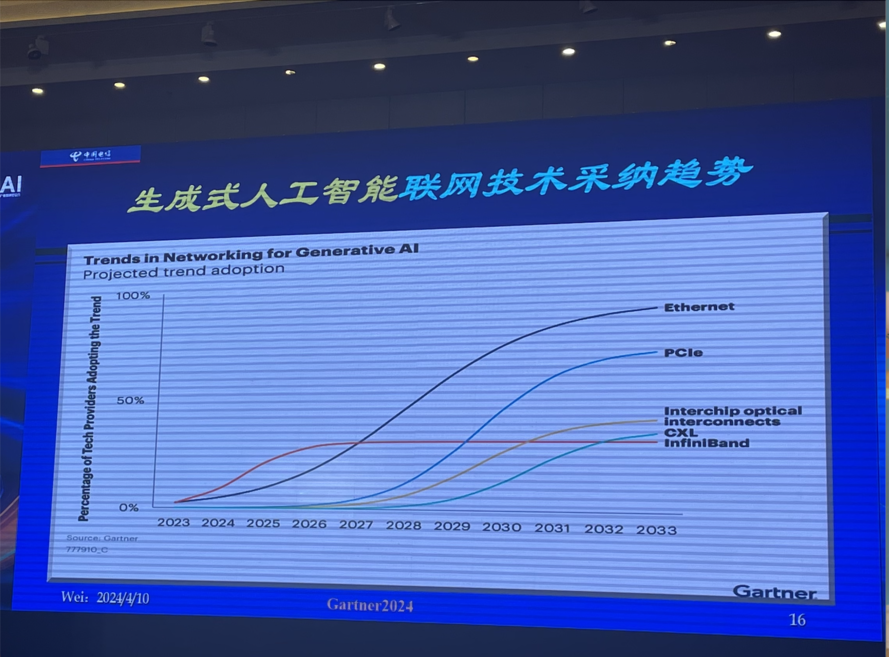
▲生成式人工智能联网技术采纳趋势
为满足大模型计算的要求,需构筑专门用于人工智能的数据中心,主要由GPU服务器联网构成。当大模型训练时,并行计算节点越多,通信效率越重要,智算网络性能成为集群算力提升的关键。
智算中心网络的要求是高带宽、零丢包、超低时延(1us)、高可靠性(月级零故障)。
目前IB性能最 优,但技术封闭,价格高。国内倾向无损以太网,但性能仍不足,时延过长,业界倾向采用增强无损以太网(如UEC)。
智算中心网络将向着超级以太网(UEC)的方向发展,UEC可重构高扩展、高稳定、高可靠的以太网堆栈,期望在性价比上全面赶上TB。
由于单站资源受限,未来可能需要在园区、AZ乃至更大范围内由多个物理集群构成一个超级逻辑集群进行联合训练才能支撑超大模型的训练。推理本身与具体业务场景相关,更可能需要跨域跨云实施。
未来大模型跨群跨域跨云的主要挑战是距离增大导致时延变大,高频次通信的效率将降低,导致网络吞吐量降低,影响GPU利用率。此外,故障概率也将增大。
对此,主要对策是解决不同集群间参数的传递和同步,以及大量数据跨群跨域跨云传输的不同时延导致的训练速度减慢的问题。
训练任务被拆分到不同集群上实行并行训练,根据不同的训练任务和场景,采用数据并行、流水线并行、张量并行等多种不同策略。
采用空芯光纤从物理层上直接降低数据传递时延(降33%)。
单站单园区集中训练是首选,跨群跨域跨云的训练依然充满挑战!
人工智能面临的基本挑战与极限
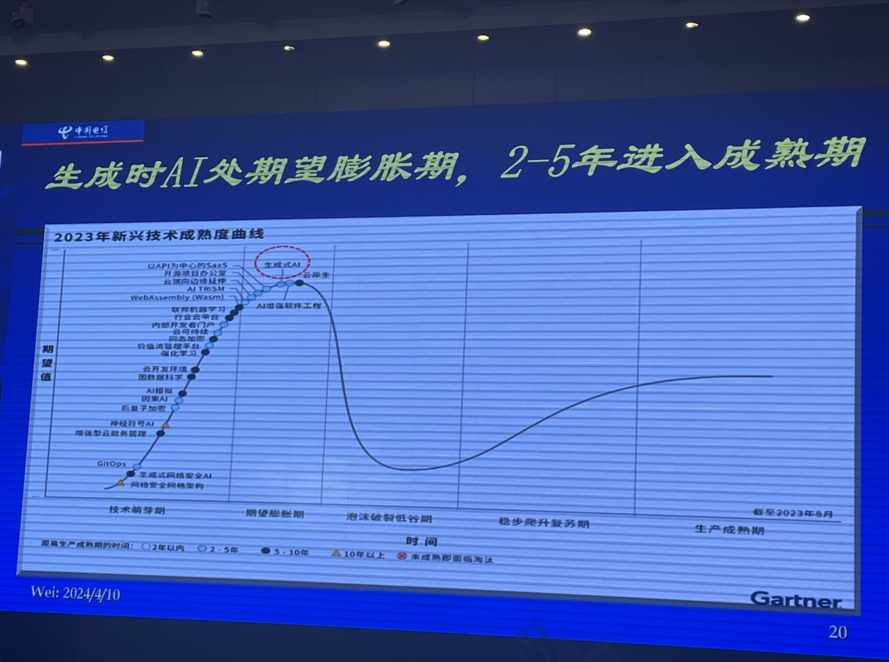
▲生成式AI处期望膨胀期,2-5年进入成熟期
近几年,人工智能特别是2023年ChatGPT的狂飙式发展现实使人们相信,人工智能不再能仅仅看作是一项能够改变未来发展和商业模型的新技术和商业工具,而将在很大程度上重塑世界格局和人类社会,影响到每一个国家、机构、企业和个人。
目前的AI依然主要是技术,还不算是科学。
AI在特定任务和工程上进步较快,但仍局限于特定的经验、场景、数据,缺乏通用能力,距离通用AI还有很长的路。
AI主要靠蛮力计算、复杂算法、高质量海量数据和运气,并未掌握核心原理,还不具备人类智能的基本特征。
人脑10的12次方个神经元和10的15次方突触构成极其复杂网络,能以很小样本和30瓦功耗实现超高计算效率和识别,而大型AI系统需百万瓦级功耗和海量数据。(例如猫狗的识别是几张照片和几千张照片之差)
深度学习已经开始遇到发展瓶颈。无法理解的算法黑盒、大力出奇迹的涌现现象、蛮力计算的巨大成本和功耗,不可控的训练结果已经成为继续高速发展的桎梏。
那么,人工智能的极限是什么?在很多感知和认知领域,计算机已经超越人类,其智能极限在哪儿无人知晓,正迈向通用人工智能将是唯一能确定的事情。
在思想、情感、道德和自主意识方面,计算机目前还难以逾越,未来怎样发展还不清楚,做好必要的防范和监管是绝对必要的。

