背景
最近从ELK日志分析发现:
有很多应用连接redis 超时;
监控平台出现”redis 集群不健康“告警;
结合之前的经验,我们一般的应处理手段为:重启连接redis超时的应用,原因有以下两点:
由于redis cluster 发生主从切换,这部分应用没有重连机制,从而导致连接超时;
部分应用使用了redis 分布式锁,可能会出现死锁的情况;
但是这次并没有像我们预想的那样将问题解决,集群仍然不健康而且主节点频繁切换。
快速定位
对于故障的快速定位,我们采用以下几个步骤:
应用版本发布是固定的发版窗口,而此问题出现于版本发布前,因此排除版本影响;
Redis cluster 是多应用公用的,因此又有以下几种情况:
某个应用批量数据导入,影响整个redis cluster,此情况大多伴随高网络流量;
某个应用执行keys、del等产生命令堵塞,此情况大多是使用规范的问题;
从以上两种情况分析,显然检查网络流量是比较简单的。
1.流量分析
在几百个应用同时使用,虽然目标单一,我们却无法直接通过监控平台的网卡流量监控来查明原因。还好我们的网络流量监控手段比较丰富,借助科来网络分析系统(前提是网络设备做好流量镜像)可以非常容易的进行流量统计。
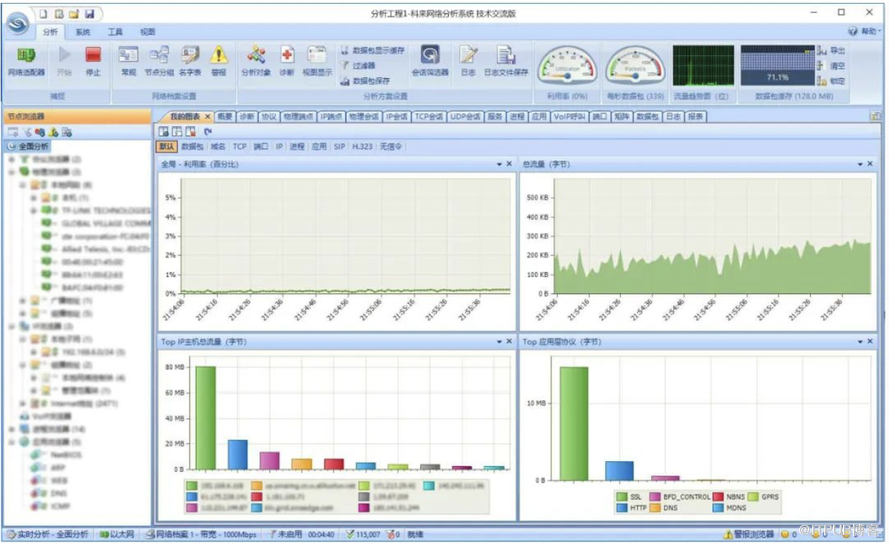
通过流量分析,很快定位某个应用和redis cluster的流量很高,经询问相关人员是在进行批量数据导入。果断叫停数据导入并观察,发现集群最终恢复正常。
比较幸运的是,虽然我们的第一种猜测就得到了验证,但运维是不能碰运气的。因此我们还需要查询命令所耗费的时间,以更好的定位是否会引起命令阻塞。
2.命令耗时
Slow log是Redis用来记录查询执行时间的日志系统。
查询执行时间指的是不包括像客户端响应(talking)、发送回复等 IO 操作,而单单是执行一个查询命令所耗费的时间。
slow log 保存在内存里面,读写速度非常快,因此你可以放心地使用它,不必担心因为开启 slow log 而损害 Redis 的速度。
「设置 SLOWLOG」
Slow log的行为由两个配置参数指定,可以通过改写 redis.conf 文件或者用 CONFIGGET 和 CONFIGSET 命令对它们动态地进行修改。
slowlog-log-slower-than ,它决定要对执行时间大于多少微秒(microsecond,1秒 = 1,000,000 微秒)的查询进行记录。
slowlog-max-len ,它决定 slow log _最多_能保存多少条日志, slow log 本身是一个 FIFO 队列,当队列大小超过 slowlog-max-len 时,最旧的一条日志将被删除,而最新的一条日志加入到 slow log ,以此类推。
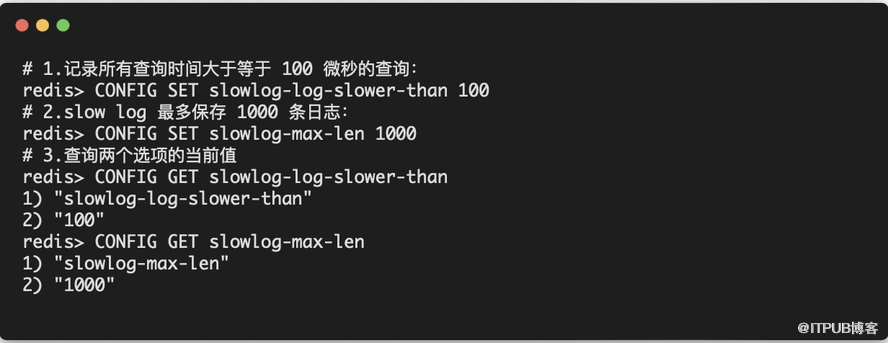
「查询命令耗时」

相对于monitor虽实时查询命令但不能进行耗时统计,而slowlog更优雅而且不会阻塞命令,因此我们可以放心使用。在实际生产中我们尽量避免使用keys *、del等命令,可以使用scan、unlink 代理。
追根溯源
1.redis日志

2.redis配置文件
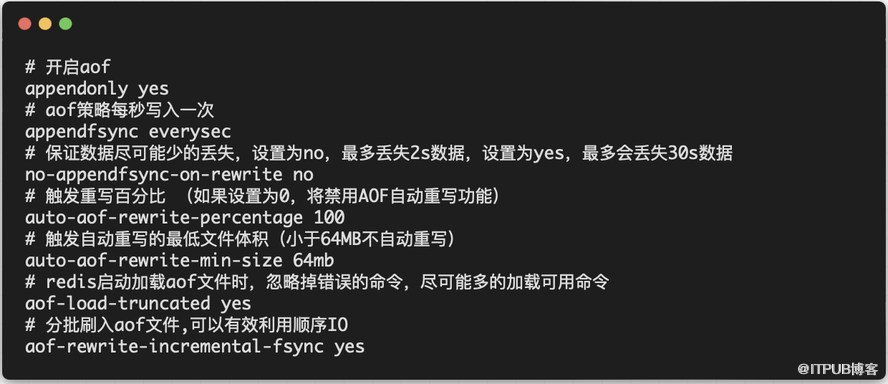
其中比较重要的参数为no-appendfsync-on-rewrite no/yes,其中:
yes:触发rewrite时,新数据执行AOF操作时不会进行fsync(),数据暂存于 aof buffer缓冲区,等待BGSAVE或BGREWRITEAOF结束后进行刷盘;
no:触发rewrite时,新数据执行AOF操作时也会进行fsync(),默认为no;
而由于此项参数我们配置为no,因此会导致没有等待fsync刷盘结束,再次触发fsync,导致redis不堪重负。
3.监控
对于redis cluster 我们目前只有状态类监控,如:
集群健康状态
集群节点数量
集群内存使用情况
但是对于核心指标类监控是缺少的,从而导致后期没有足够的运行数据来帮助我们更好的分析问题,在此我们可借鉴补充以下指标的监控。

主要从aof触发rewrite文件大小和fsync处理延时两个方面进行监控。
总结
通过本次故障的复盘,我们从以下方面有所启发:
1.第一时间以恢复系统为主,快速排除系统变更或其他操作等外部因素,根据应急预案快速重启相关应用;
2.监控平台固然重要,但也要善于结合流量统计、抓包、安全等外部工具来排查问题;
3.对于中间件或其他公共组件,监控平台只有状态监控,缺少性能或核心指标监控;

