首先介绍了QUIC多进程部署架构,随后分析了QUIC网络架构在生产应用中遇到的问题及其优化方案。在性能提升方面,分享了QUIC全链路埋点监控的实现思路及其收获,QUIC拥塞控制算法开发与调优思路等等。希望这些内容能够帮助大家了解QUIC协议及其在实际应用中的优化思路,并从中获得启发。
一、前言
1.1 QUIC在Trip.com APP的落地简介
QUIC(Quick UDP Internet Connections)是由Google提出的基于UDP的传输层协议,为HTTP3的标准传输层协议。相较于TCP协议,QUIC主要具备以下优势:
1)多路复用:QUIC允许在单个连接上并行传输多个数据流,解决了TCP的队头阻塞问题,从而提高了传输效率;
2)快速建连:新建连时,QUIC握手与TLS握手并行,避免了TLS单独握手所消耗的1个RTT时延。当用户连接过期失效且在PSK(pre-shared key)有效期内再次建连时,QUIC通过验证PSK复用TLS会话,实现0-RTT建联,从而可以更快的建立连接,此特性在短连接,单用户低频请求的场景中收益尤为明显;
3)连接迁移:TCP通过四元组标识一个连接,当四元组中的任一部分发生变化时,连接都会失效。而QUIC通过连接CID唯一标识一个连接,当用户网络发生切换(例如WIFI切换到4G)时,QUIC依然可以通过CID找到连接,完成新路径验证继续保持连接通信,避免重新建连带来的耗时;
4)拥塞控制:TCP的拥塞控制需要操作系统的支持,部署成本高,升级周期长,而QUIC在应用层实现拥塞控制算法,升级变更加灵活;
上述优质特性推动了QUIC协议在IETF的标准化发展,2021年5月,IETF推出了QUIC的标准化版本RFC9000,我们于2022年完成了QUIC多进程部署方案在Trip.com APP的落地,支持了多进程下的连接迁移和0-RTT特性,最终取得了Trip.com App链路耗时缩短20%的收益,大大的提升了海外用户的体验。我们的初期网络架构如下:
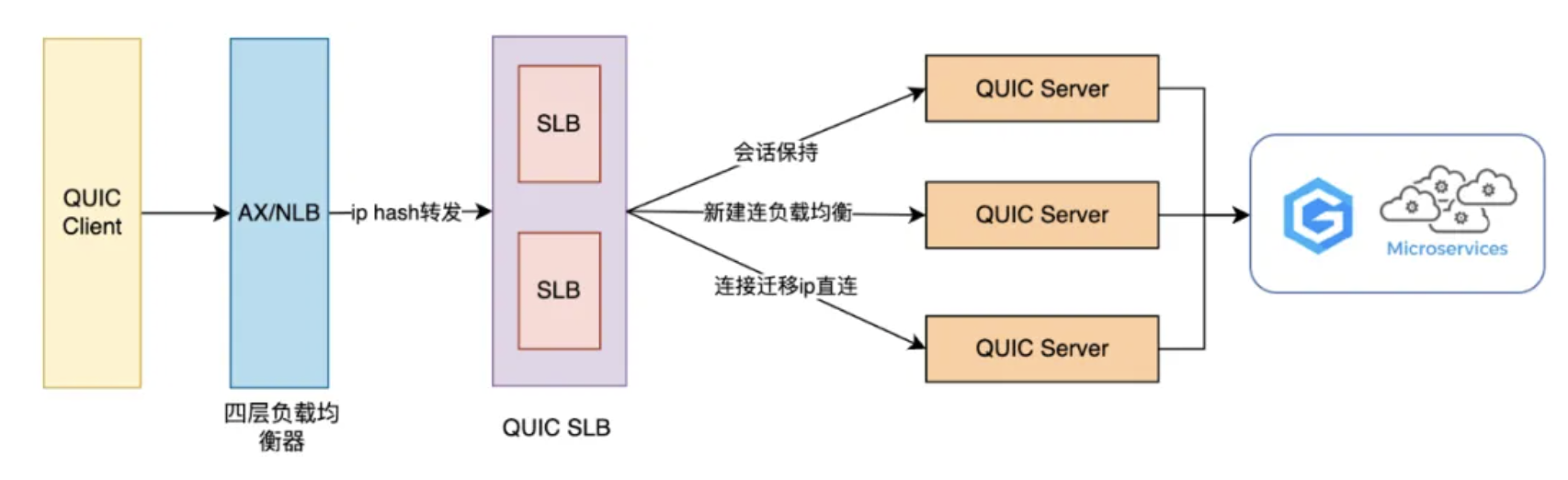
其中有两个重要组成部分,QUIC SLB和QUIC Server:
QUIC SLB工作在传输层,具有负载均衡能力,负责接收并正确转发UDP数据包至Server。当用户进行网络切换,导致连接四元组发生变化时,SLB通过从连接CID中提取Server端的ip+port来实现数据包的准确转发,从而支持连接迁移功能;
QUIC Server工作在应用层,是QUIC协议的主要实现所在,负责转发及响应客户端请求,通过Server集群共享ticket_key方案实现0-RTT功能;
1.2 QUIC高可用及性能提升
随着全球旅游业的复苏,携程在国内外的业务迎来了成倍的增长,业务体量越来越庞大,QUIC作为Trip.com APP的主要网络通道,其重要性不言而喻。为了更好地应对日益增长的流量,更稳定地支持每一次用户请求的送达,我们建立了QUIC高可用及性能提升的目标,最终完成了以下优化内容:
QUIC集群及链路高可用优化:
完成QUIC Server容器化改造,具备了HPA能力,并定制化开发了适用于QUIC场景的HPA指标
优化QUIC网络架构,具备了QUIC Server的主动健康监测及动态上下线能力
通过推拉结合的策略,有效提升了客户端App容灾能力,实现网络通道和入口ip秒级切换
搭建了稳定可靠的监控告警体系
QUIC成功率及链路性能提升:
支持QUIC全链路埋点,使QUIC运行时数据更加透明化
通过优化拥塞控制算法实现了链路性能的进一步提升
通过多Region部署缩短了欧洲用户20%的链路耗时
客户端Cronet升级,网络请求速度提升明显
QUIC应用场景拓展:
支持携程旅行App和商旅海外App接入QUIC,国内用户和商旅用户在海外场景下网络成功率和性能大幅提升
下文将详细的介绍这些优化内容。
二、QUIC网络架构升级
2.1 容器化改造
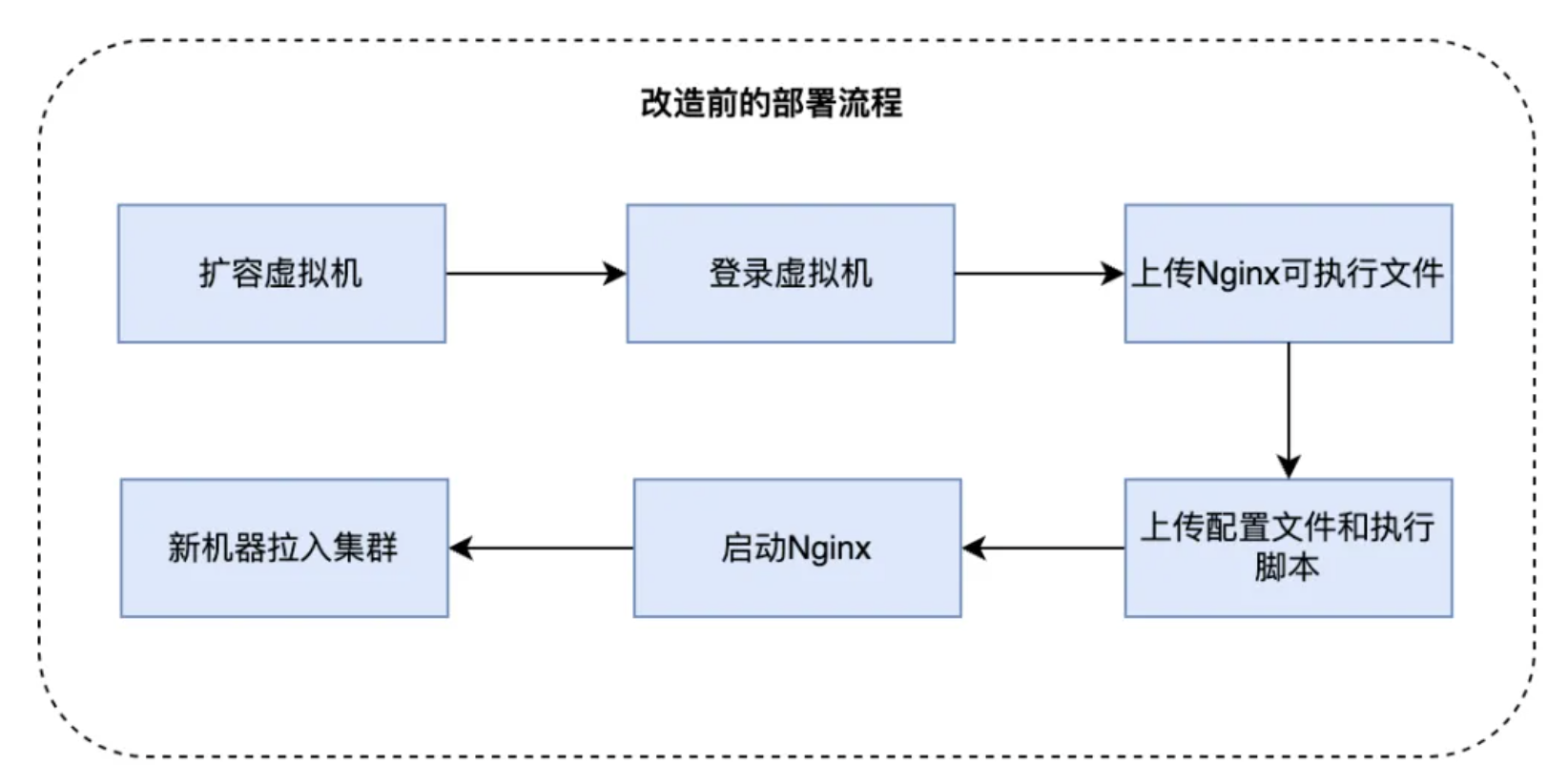
改造前我们统一使用VM部署QUIC SLB和QUIC Server,具体部署流程如下:
QUIC实践早期我们经常需要在机器上执行自定义操作,这种部署方案的优点是比较灵活。但随着QUIC服务端功能趋于稳定,以及业务流量的日益增长,此方案部署时间长、不支持动态扩缩容的弊端日益显现。为了解决以上问题,我们对QUIC SLB以及QUIC Server进行了容器化改造:
QUIC Server承载了QUIC协议处理以及用户http请求转发这两项核心功能,我们将其改造成了容器镜像,并接入到内部Captain发布系统中,支持了灰度发布,版本回退等功能,降低了发布带来的风险,同时具备了HPA能力,扩缩容时间由分钟级缩短到秒级
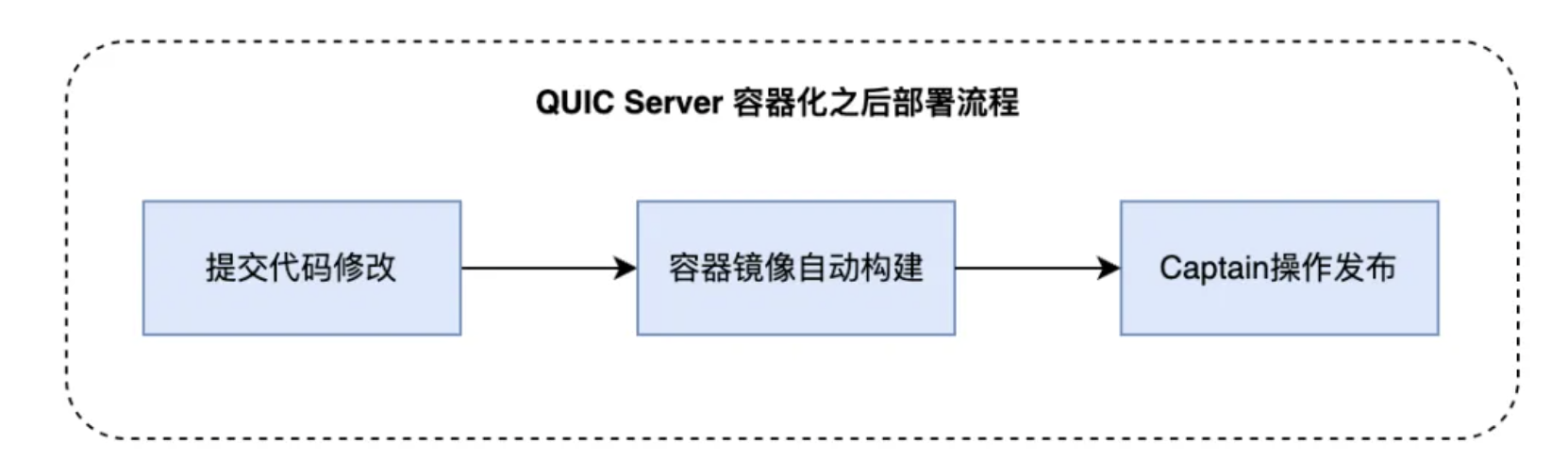
QUIC SLB作为外网入口,主要负责用户UDP包的转发,负载较小,对流量变化不敏感。并且由于需要Akamai加速,QUIC SLB需要同时支持UDP以及TCP协议,当前容器是无法支持双协议的外网入口的。因此我们将QUIC SLB改造成了虚拟机镜像,支持在PaaS上一键扩容,大大降低了部署成本
2.2 服务发现与主动健康监测
在QUIC SLB中,我们使用Nginx作为4层代理,实现QUIC UDP数据包的转发以及连接迁移能力。
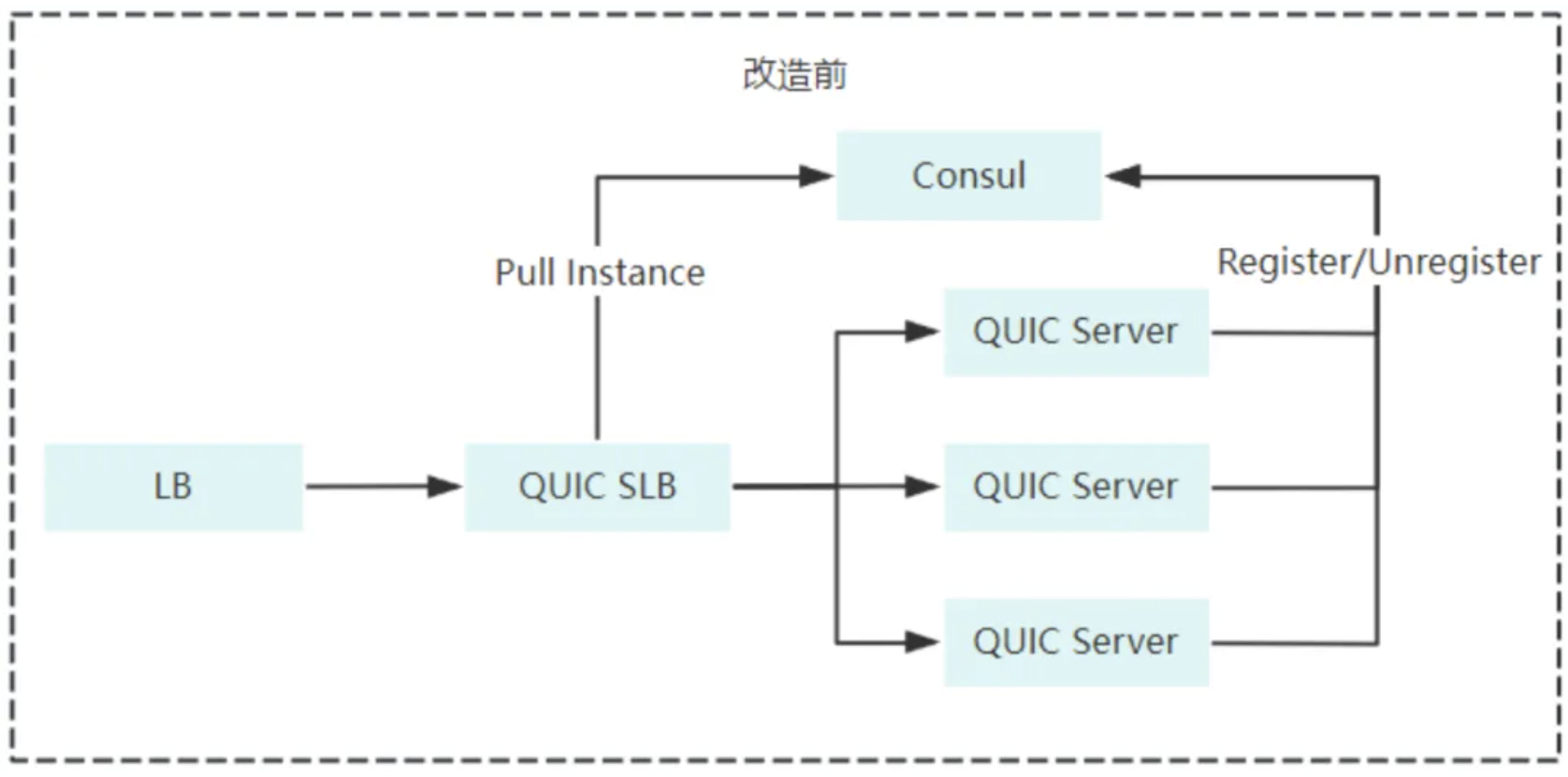
容器化后的前期我们使用Consul作为QUIC Server的注册中心,Server会在k8s提供的生命周期函数postStart和preStop中分别调用Consul的注册和删除API,将自身ip在Consul中注册或摘除。QUIC SLB会监听Consul中ip的变化,从而及时感知到每个Quic Server的状态,并实时更新到Nginx的配置文件中,这样就实现了QUIC Server的自动注册与发现。
但在实际演练场景中,我们发现当直接对QUIC Server注入故障时,由于Server所在pod并没有被销毁,因此不会触发preStop API的调用,故障Server无法在Consul中摘除自身ip,导致QUIC SLB无法感知到Server的下线,因此QUIC SLB的nginx.conf中依旧会保留故障的Server ip,这种情况在Nginx做TCP代理和UDP代理时所产生的影响不同:
当Nginx做TCP代理时,Nginx与故障Server之间建立的是TCP连接,Server故障时TCP连接会断开,Nginx会与故障Server重新建联但最终失败,此时会自动将其拉出一段时间,并每隔一段时间进行探测,直至其恢复,从而避免了TCP数据包转发至错误的Server,不会导致服务成功率下降;
当Nginx做UDP代理时,由于UDP是无连接的,QUIC SLB依旧会转发数据包至故障Server,但SLB不会收到任何响应数据包,由于UDP协议特性,此时QUIC SLB不会判定Server为异常,从而持续大量的UDP包被转发到故障Server实例上,导致QUIC通道的成功率大幅下降;
经过上述分析,我们知道了使用UDP进行健康监测存在一定弊端,期望使用TCP协议对QUIC Server进行主动的健康检测。所以开启了新方案的探索,其需要同时支持UDP数据转发,基于TCP协议的主动健康监测,支持服务发现与注册,并且能够较好的适配QUIC SLB层。
调研了很多方案,其中较适配的是开源的Nginx UDP Health Check项目,其同时支持UDP数据包转发和TCP的主动健康检测,但是其不支持nginx.conf中下游ip的动态变更,也就是不支持QUIC Server的动态上下线,这直接影响了Server集群的HPA能力,因此舍弃了这个方案。
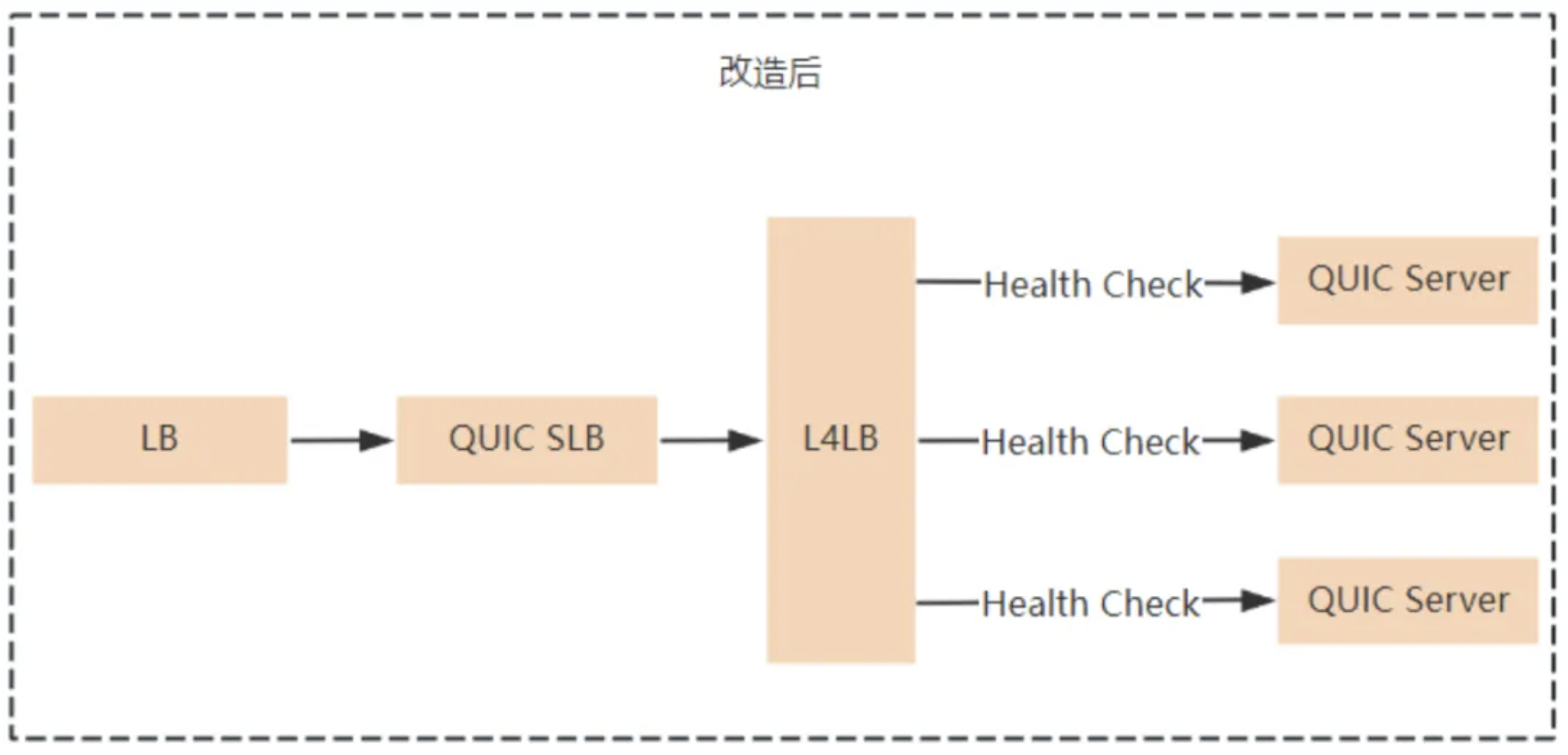
最终通过调研发现公司内部的L4LB组件,既能同时支持TCP的主动健康检测和UDP数据包转发,还支持实例的动态上下线,完美适配我们的场景,因此最终采用了L4LB作为QUIC SLB和QUIC Server之间的转发枢纽。
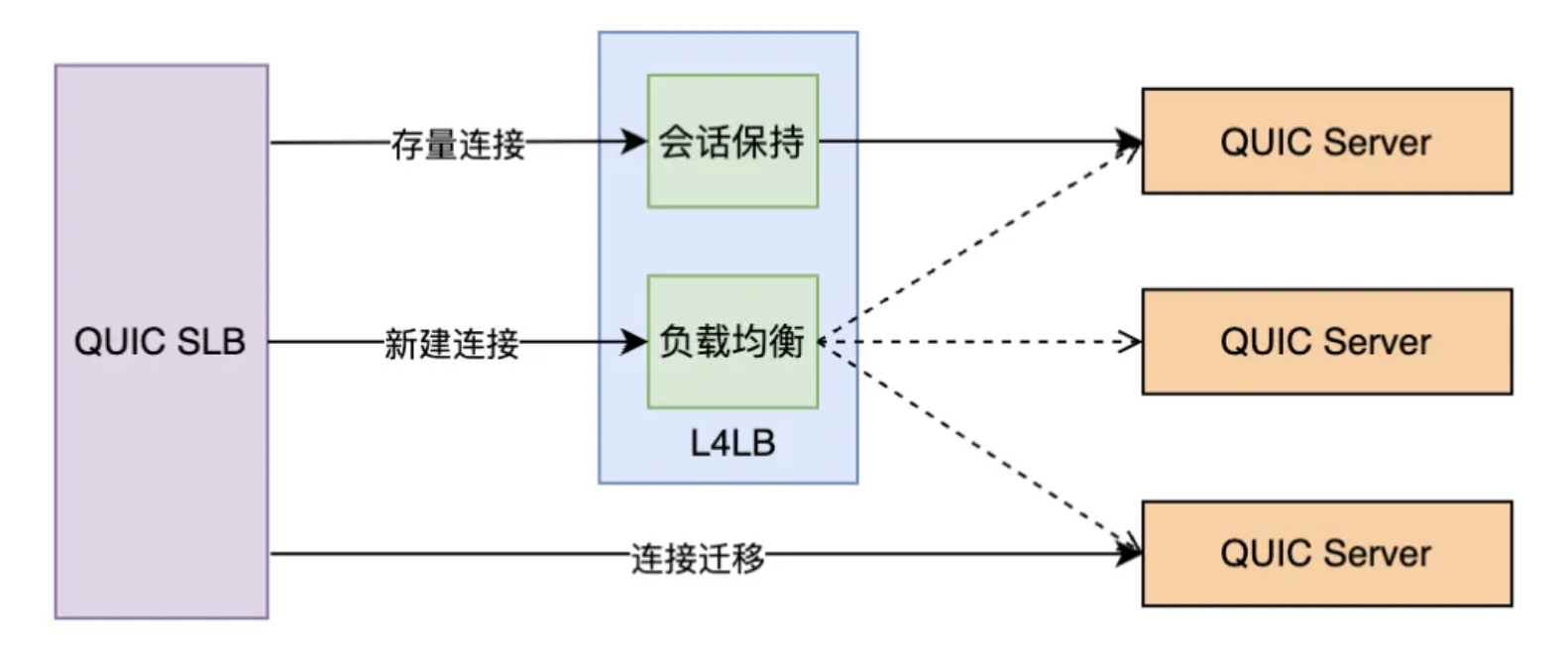
具体实现是为QUIC Server的每个group申请一个UDP的内网L4LB入口ip,这些ip是固定不变的,那么对于QUIC SLB来说只需要将UDP数据包转发至固定的虚拟ip即可。L4LB开启TCP的健康检测功能,这样当group中的QUIC Server实例故障时,健康检测失败,L4LB就会将此实例拉出,后续UDP包就不会再转发到此实例上,直至实例再次恢复到健康状态。这样就完美解决了QUIC Server的自动注册与主动健康监测功能。
2.3 推拉结合方式提升客户端用户侧网络容灾能力
Trip.com App的网络请求框架同时支持QUIC/TCP/HTTP 三通道能力,其中80%以上的用户请求都是通过QUIC通道访问服务器的,日均流量达到数亿,在现有的多通道/多IP切换能力的基础上,进一步提升容灾能力显得尤为重要。于是我们设计了一套推拉结合的策略方案,结合公司配置系统实现了秒级通道/IP切换。下面是简化过程:
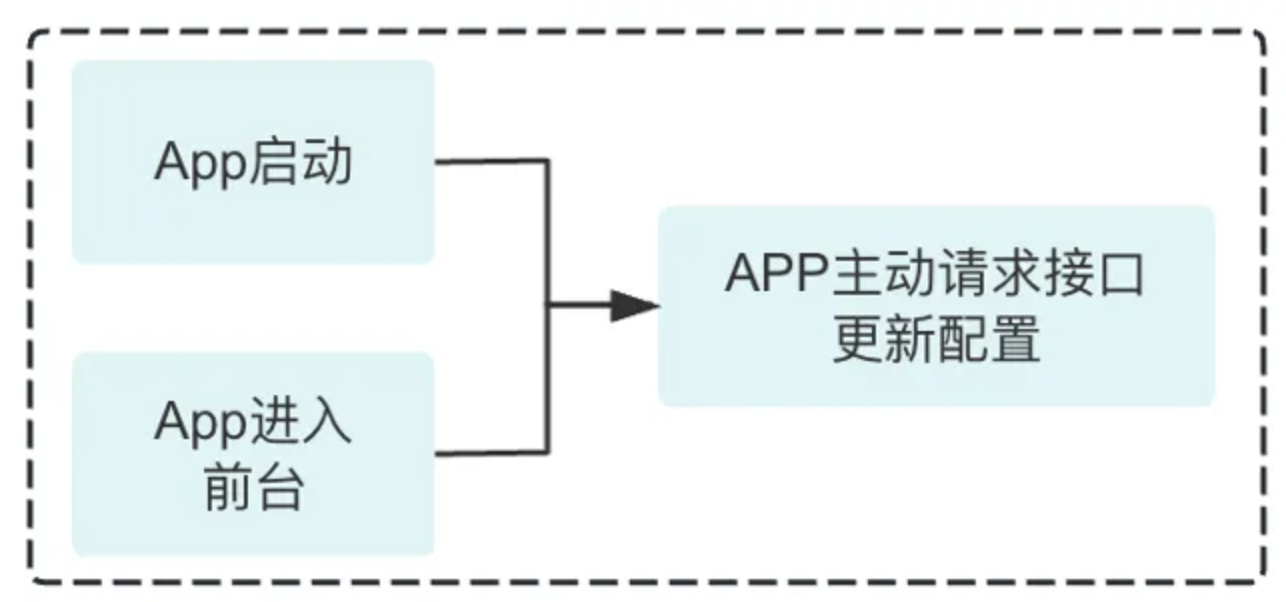
在客户端App启动和前后台切换等场景,根据变动情况获取最新的配置,网络框架基于最新的配置进行无损通道或IP的切换。
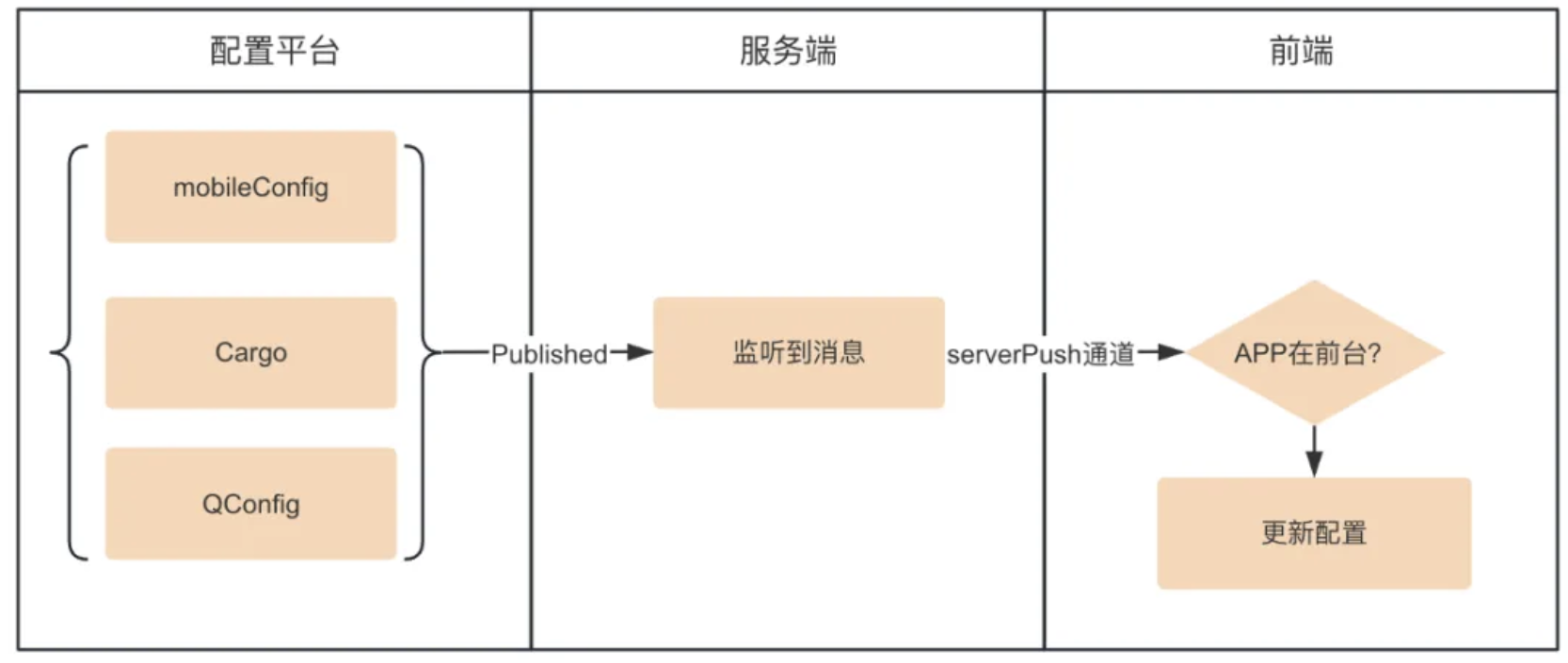
同时当用户APP处于前台活跃状态时,通过对用户进行主动的配置更新推送,让在线用户可以立即感知到变化并切换至最新的网络配置上面,且此切换过程对用户是无感的。
这样一来,我们的QUIC客户端网络框架进一步提升了容灾能力,当某个IP发生故障时,可以在秒级通知所有用户切离故障IP,当某通道发生异常时,用户亦可以无感的切换至优质通道,而不会受到任何影响。
2.4 监控告警稳定性保证及弹性扩缩容指标建设
QUIC数据监控系统的稳定性,对于故障预警、故障响应起到至关重要的作用。通过将埋点数据写至access log和error log来完成QUIC运行时埋点数据的输出,再通过logagent将服务器本地的日志数据发送至Kafka,随后Hangout消费并解析,将数据落入Clickhouse做数据存储及查询,这给我们做运行时数据观察及数据分析提供了很大的便利性。
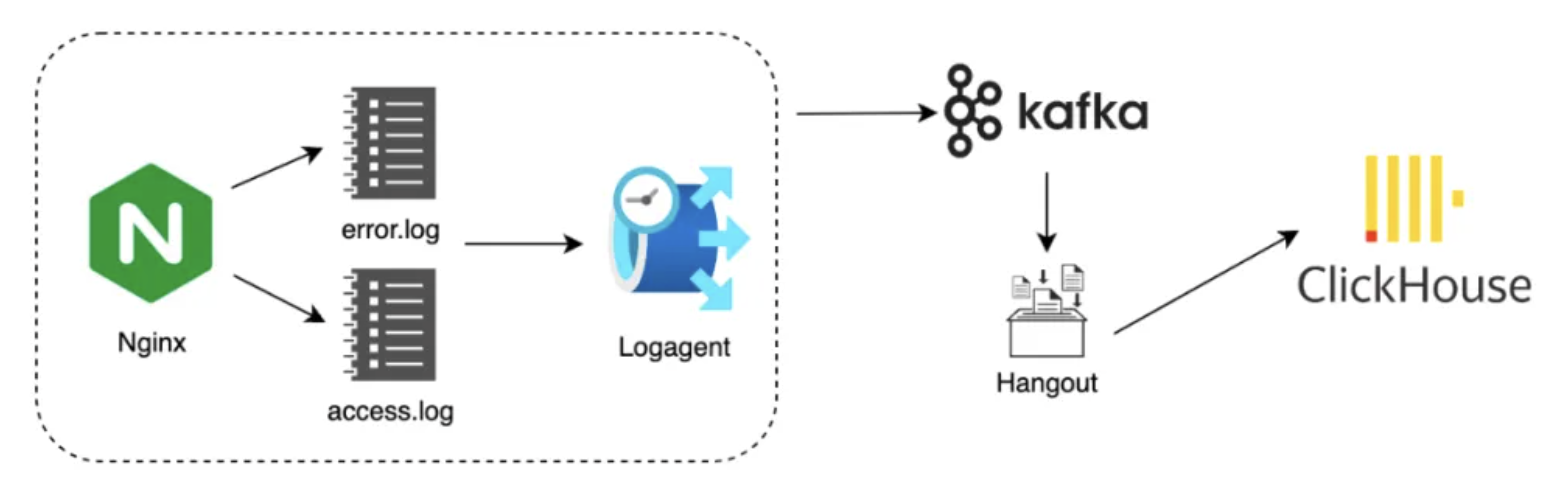
在完成QUIC网络架构升级之后,只依靠上述日志体系遇到了下面两类问题:
第一,在应用场景下,单纯依靠这部分数据做监控告警,偶发由于某些中间环节出现波动导致监控告警不准确, 例如Hangout消费者故障导致流量骤降或突增的假象,这可能会影响监控告警的及时性和准确性;
第二,容器化之后具备了弹性扩缩容能力,而HPA依赖于扩缩容数据指标,仅仅使用CPU、内存利用率等资源指标,无法充足的反映QUIC服务器状态。根据QUIC服务特性,仍需要自定义一些HPA数据指标,例如空闲连接占比,空闲端口号占比等,以建立更合理、更稳定的扩缩容依赖;
基于上述两方面的考量,在经过调研之后,我们将Nginx与Prometheus进行整合,支持了关键数据指标、扩缩容数据指标通过Prometheus上报的方案。在Nginx中预先对成功率,耗时,可用连接数等等重要指标进行了聚合,只上报聚合数据指标,从而大大缩小了数据体量,使Nginx整合Prometheus的影响可以忽略不计。另外我们支持了空闲连接占比,空闲端口号占比等等HPA指标,使QUIC集群在流量高峰期,能够非常准确迅速的完成系统扩容,在低流量时间段,也能够缩容至适配状态,以最大程度的节约机器资源。
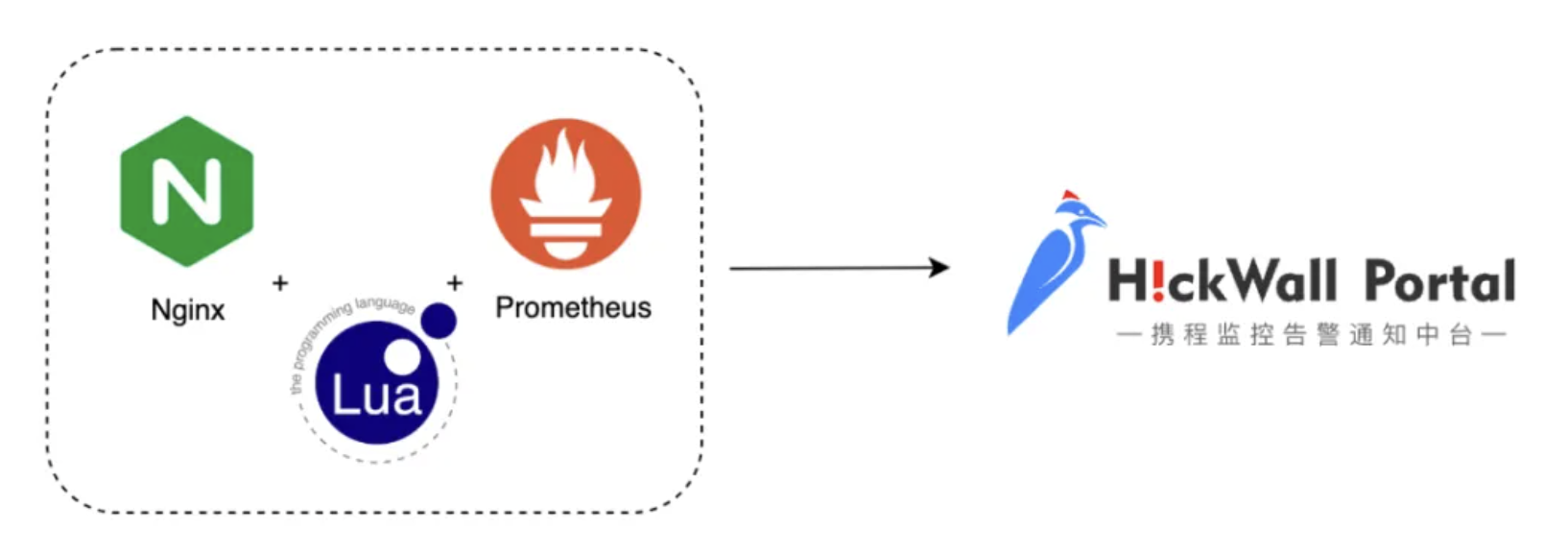
这样一来,QUIC系统的监控告警数据来源同时支持Prometheus和Clickhouse,Prometheus侧重关键指标及聚合数据的上报,Clickhouse侧重运行时明细数据的上报,两者相互配合互为补充。
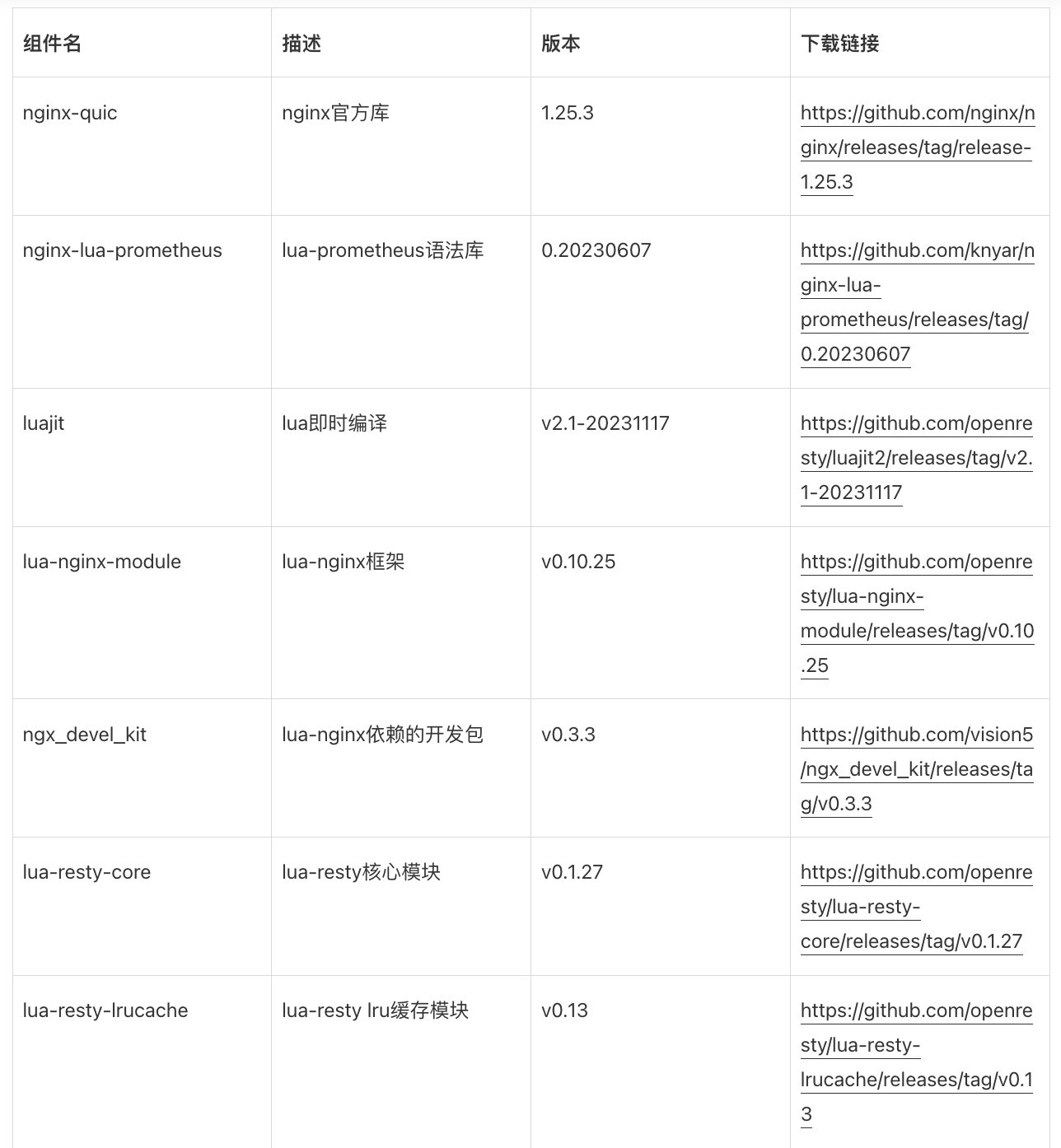
在支持Prometheus过程中我们遇到了较多依赖项的版本搭配导致的编译问题,以nginx/1.25.3版本为例,给出版本匹配结果:
三、全链路埋点
3.1 落地实践
我们基于优化用户链路耗时,寻找并优化耗时短板的目标出发,开始抽样分析耗时较久的请求,并根据所需,在服务端access.log中逐渐添加了较多的数据埋点,nginx官方对单个http请求维度的数据埋点支持性较好,但仅仅分析单个请求维度的信息,难以看清请求所属连接的各类数据,仍需要观察用户连接所处网络环境,握手细节,数据传输细节,拥塞情况等等数据,来协助对问题进行定位。
QUIC客户端之前仅有端到端的整体埋点数据,并且存在QUIC埋点体系和现有体系mapping的问题,我们收集过滤Cronet metrics的信息,整合进现有埋点体系内。
3.1.1 收集过滤QUIC客户端Cronet Metrics埋点数据
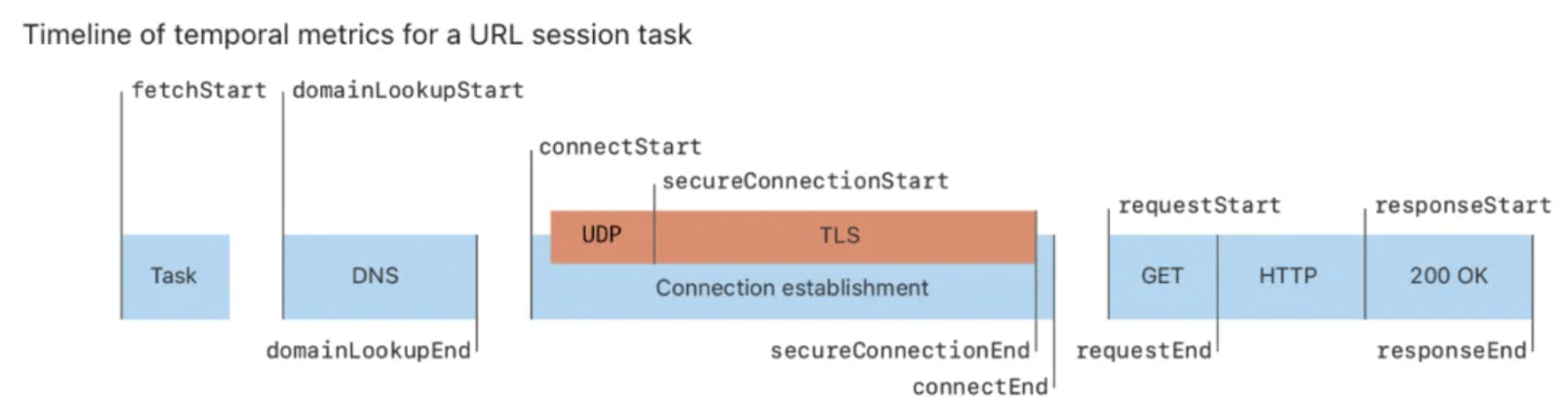
端到端流程支持了DNS、TLS握手、请求发送、响应返回等环节细粒度的埋点,QUIC端到端各环节数据一目了然。
3.1.2 改造服务端nginx源码
我们在连接创建到连接销毁的全生命周期内进行了详细的数据埋点,另外通过连接CID实现了连接级别埋点和请求级别埋点数据的串联,这对进行问题定位,性能优化等提供了可靠的数据支持。下面分类列举了部分服务端全链路埋点,并简要概述了其用途:
1)连接生命周期时间线
连接类型(1-rtt/0-rtt),连接创建时间(Server收到Client第一个数据包的时间),连接发送第一个数据包的时间,连接收到第一个ack帧的时间,连接握手耗时,连接收到及发送cc帧(Connection Close Frame)的时间,连接无响应超时时间,连接销毁时间等等;这一类埋点主要帮助我们理清用户连接生命周期中的各个关键时间点,以及握手相关的耗时细节。
2)数据传输细节
(以下皆为连接生命周期内)发送和接收字节、数据包、数据帧总数,包重传率,帧重传率等等。这类数据帮助分析我们的数据传输特性,对链路传输优化,拥塞控制算法调整提供数据参考。
3)RTT(Round-trip time)和拥塞控制数据
平滑RTT,最小RTT,首次和最后一次RTT,拥塞窗口大小,最大in_flight,慢开始阈值,拥塞recovery_start时间等等。这些数据可用来分析用户网络状况,观察拥塞比例,评估拥塞控制算法合理性等等。
4)用户信息
客户端ip,国家及地区等。这帮助我们对用户数据进行区域级别的聚合分析,找到网络传输的区域性差异,以进行一些针对性优化。
3.2 分析挖掘
通过合并聚合各类数据埋点,实现了QUIC运行时数据可视化透明化,这也帮助我们发现了诸多问题及优化项,下面列举几项进行详述:
3.2.1 0-rtt连接存活时间异常,导致重复请求问题
通过筛选0-rtt类型的连接,我们观察到此类连接的存活总时间,恰好等于QUIC客户端和服务端协商之后的max_idel_timeout,而max_idel_timeout的准确定义为”连接无响应(客户端服务端无任何数据交互)超时关闭时间“,也就是说正常情况下,当一个连接上最后一次http请求交互完毕之后,若经过max_idel_timeout时间仍未发生其他交互时,连接会进入关闭流程;当连接上不断的有请求交互时,连接的存活时间必定大于max_idel_timeout(实际连接存活时间 = 最后一次请求数据传输完成时间 - 连接创建时间 + max_idel_timeout)。
为了论证上述现象,我们通过连接的dcid,关联筛选出0-rtt连接生命周期中所有http请求列表,发现即使连接上的请求在不断的进行,0-rtt连接仍然会在存活了max_idel_timeout时无条件关闭,所以断定0-rtt连接的续命逻辑存在问题。我们对nginx-quic源码进行阅读分析,最终定位并及时修复了问题代码:
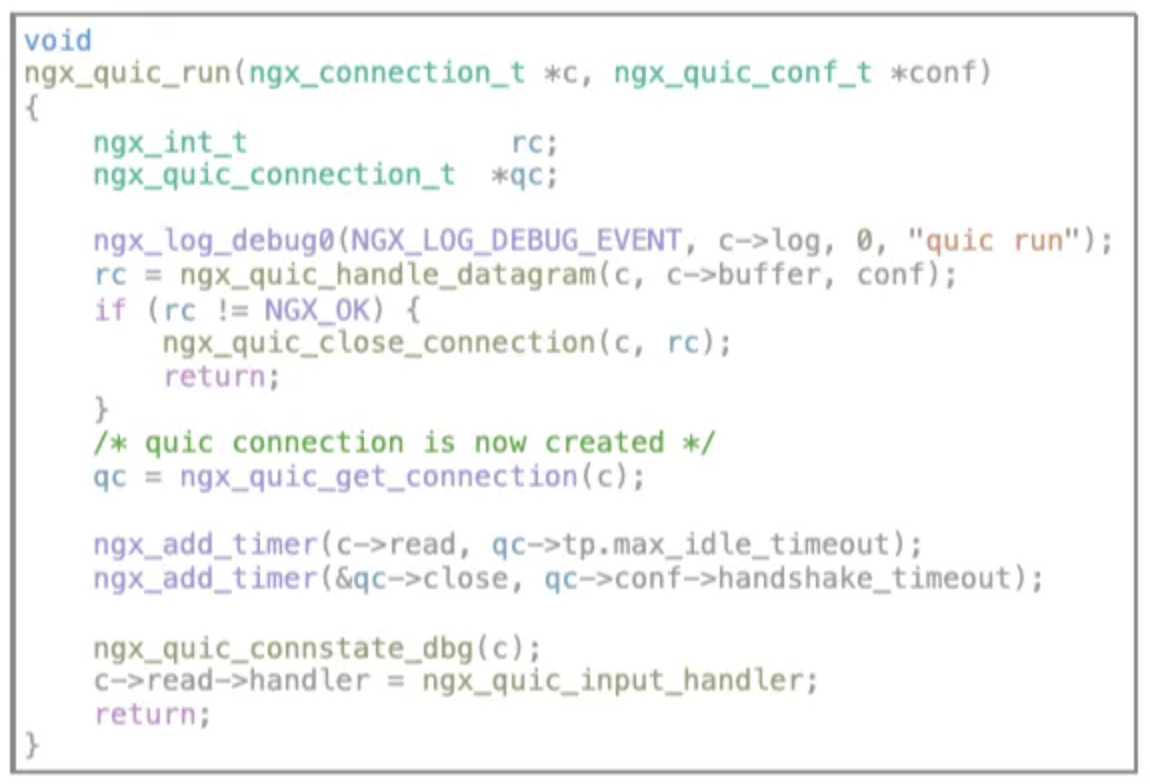
在源码ngx_quic_run()函数中,存在两个连接相关的定时器:

两者都会影响连接的关闭,其中c->read定时器存在续命逻辑,会随着连接生命周期内,请求的不断发生而刷新定时器。qc->close在源码中不存在续命逻辑,有且仅有一处删除逻辑,即在执行ngx_quic_handle_datagram()函数过程中,若完成了ssl初始化,则调用ngx_quic_do_init_streams()进行qc->close定时器的删除操作;
若为1-rtt建联,第一次执行ngx_quic_handle_datagram()函数不会完成ssl初始化,所以qc->close的创建发生在ssl初始化完毕之前,在后续数据包交互过程中能够正常完成删除逻辑;
若为0-rtt建联,第一次执行ngx_quic_handle_datagram()函数会完成ssl初始化逻辑,所以仅一次的删除逻辑,发生在了qc->close定时器设置之前,所以导致qc->close不能被正常移除,从而导致max_idel_timeout时间一到,连接立即关闭的现象;
这个bug除了导致较多无效0-rtt新建连之外,在我们的应用场景下,经过对全链路埋点数据聚合分析发现,还会导致重复请求问题,下面介绍发生重复请求的原因:
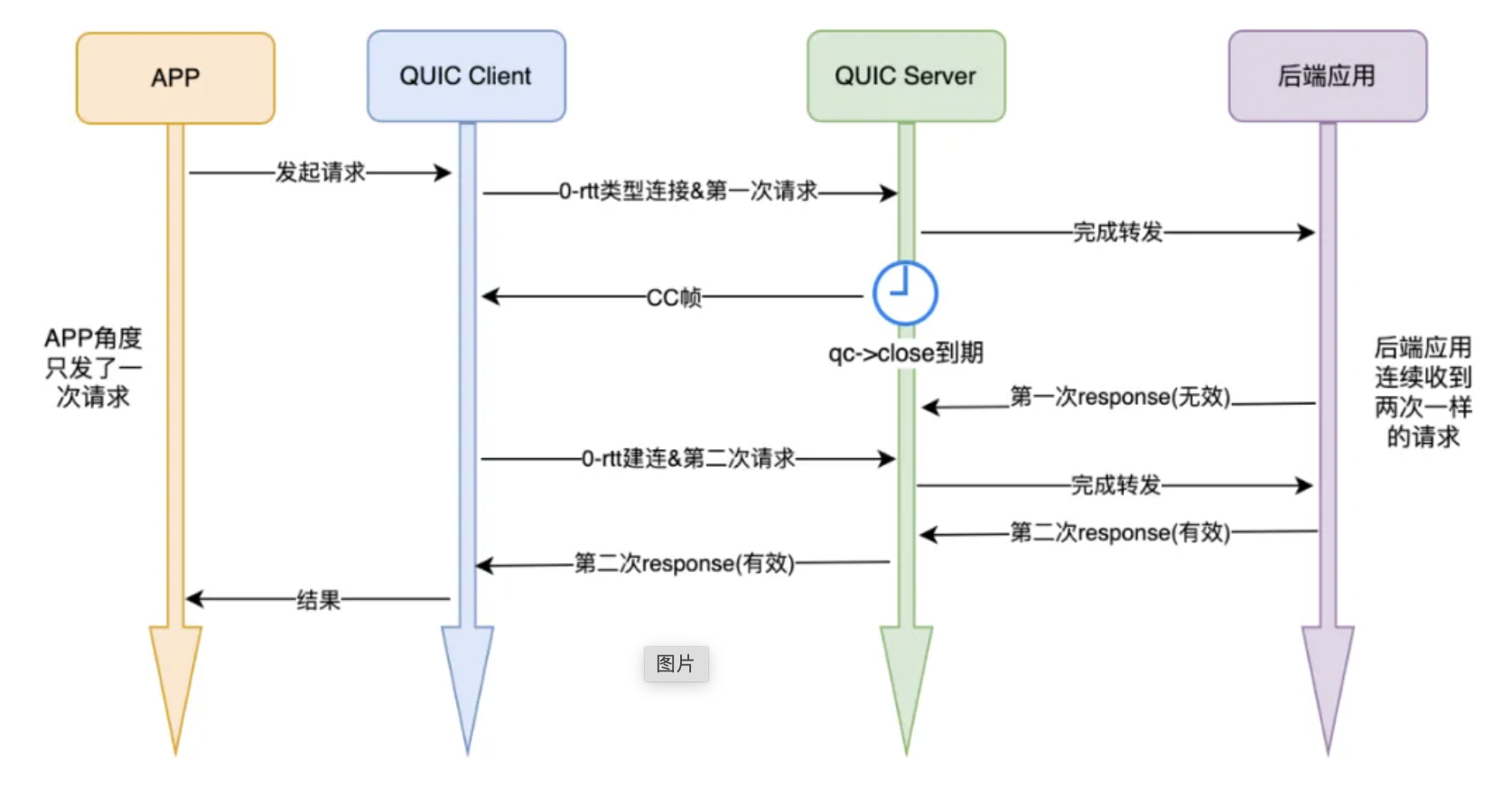
quic client发起某个request的第一次请求,quic server端收到并转发给后端应用,在server收到后端应用response之前,恰好qc->close定时器到期,导致server立即向client发送cc帧,client在收到cc帧后,按照quic协议应无条件立即关闭当前连接,所以client认为第一次请求失败,从而发起新建连,开始第二次请求,从而导致重复请求问题。而这个过程从客户端业务角度来说只请求了一次,但后端应用却连续收到两次一模一样的请求,这对于幂等性要求较高的接口影响较大。
我们在2024年2月发现并修复了上述定时器bug,修复之后连接复用比例提升0.5%,不必要的0-rtt建连比例降低7%。目前nginx-quic官方分支于2024/04/10也提交了对此问题的修复,Commit链接:https://hg.nginx.org/nginx-quic/rev/155c9093de9d
3.2.2 客户端App Cronet升级给95线用户带来体验提升
经过数据分析发现,长尾用户在0-RTT上占比不高,大多为1-RTT新建连接,经过分析判断可能和QUIC客户端Cronet裁剪有关。Trip.com App上Cronet库在优化前使用的是2020年的旧版本,并且由于包大小问题对其进行了裁剪(比如:重构了PSK相关逻辑,转为session级别),在保留关键功能的前提下尽可能剔除了无用代码十几万行。同时经过与其他Cronet使用方沟通,得到Cronet升级后有不错的性能提升表现,于是时隔近四年,客户端对Cronet库进行了一次大升级。
另外,由于Chromium官方在2023年11月份官宣不再提供iOS的Cli工具,所以此次升级目标就定位选一个尽可能靠近官方删除iOS构建工具之前的版本,最终我们选定了 120.0.6099.301。

经过Cronet升级及相关适配性改造,对线上升级前后版本进行对比,升级后用户侧95线请求耗时降低了18%。
3.2.3 Nginx-quic分支中拥塞控制算法实现具有较大的优化空间
通过对nginx-quic源码的研究以及链路埋点的数据分析,我们发现源码中的拥塞控制算法为Reno算法的简化版,初始传输窗口设置较大为131054字节(若mtu为1200,初始就有109个包可以同时传输)。若发生拥塞事件,降窗的最小值仍为131054字节,在网络较好时,网络公平性不友好,在网络较差时,这会加剧网络拥堵。在发现此问题后,我们开始着手改造源码中的拥塞控制算法逻辑,这一优化内容将在第四部分详述。
四、拥塞控制算法探索
nginx-quic官方分支中,对于拥塞控制算法的实现目前仍处于demo级别,我们结合QUIC在应用层实现拥塞控制算法而不依赖于操作系统的特性,对Nginx官方代码中拥塞控制相关逻辑进行了抽象重构,以方便拓展各种算法,并支持了可配置式的拥塞控制算法切换,可以根据不同的网络状况,不同的server业务场景配置不同的拥塞控制算法。
4.1 拥塞控制算法简介
目前主流的拥塞控制算法大抵可分为两类,一类是根据丢包做响应,如Reno、Cubic,一类是根据带宽和延迟反馈做响应,如BBR系列。这里简要介绍下Reno,Cubic和BBR的工作原理,适用场景及优缺点:
1)Reno算法是TCP最早的拥塞控制算法之一,基于丢包的拥塞控制机制。它使用两个阈值(慢启动阈值和拥塞避免阈值)来控制发送速率。在慢启动阶段,发送方每经过一个往返时间(RTT),就将拥塞窗口大小加倍。一旦出现拥塞,会触发拥塞避免阶段,发送速率会缓慢增长。当发生丢包时,发送方会认为发生了拥塞,将拥塞窗口大小减半;适用于低延时、低带宽的场景,对于早期互联网环境比较适用。其优点是简单直观,易于理解和实现。缺点是对网络变化反应较慢,可能导致网络利用率不高,且在丢包率较高时性能不佳。
2)Cubic算法在Reno算法的基础上进行改进,利用网络往返时间(RTT)和拥塞窗口的变化率来计算拥塞窗口的大小,使用拟立方函数来模拟网络的拥塞状态,并根据拥塞窗口的大小和时间来调整拥塞窗口的增长速率。适用于中度丢包率的网络环境,对于互联网主流环境有较好的性能表现。优点是相对于Reno算法,能更好地适应网络变化,提高网络利用率。缺点是在高丢包率或长肥管道环境下,发送窗口可能会迅速收敛到很小,导致性能下降。
3)BBR(Bottleneck Bandwidth and RTT)算法是Google开发的一种拥塞控制算法,通过测量网络的带宽和往返时间来估计网络的拥塞程度,并根据拥塞程度调整发送速率。BBR算法的特点是能够更精确地估计网络的拥塞程度,避免了过度拥塞和欠拥塞的情况,提高了网络的传输速度和稳定性。适用于高带宽、高延时或中度丢包率的网络环境。优点是能够更精确地控制发送速率,提高网络利用率和稳定性。缺点是可能占用额外的CPU资源,影响性能,且在某些情况下可能存在公平性问题。
4.2 优化实现及收益
源码中有关拥塞控制逻辑的代码分散在各处功能代码中,未进行抽象统一管理,我们通过梳理拥塞控制算法响应事件,将各个事件函数抽象如下:

我们基于上述抽象结构,先后实现了目前主流的拥塞控制算法Reno,Cubic及BBR,并且我们根据埋点数据对拥塞控制算法进行了参数和逻辑调优,包括设置合理的初始窗口和最小窗口,设置最优的拥塞降窗逻辑等等,这些调整会引起包重发率和连接拥塞率的数据变化,而这些数据变化皆会影响到链路传输性能。
我们通过对QUIC拥塞控制算法的优化,SHA环境连接拥塞比例降低了15个点,实现了SHA端到端耗时降低4%的收益。后续将继续基于Trip.com的数据传输特性,根据每个IDC的不同网络状况进行适应性定制化开发,并通过长期的AB实验,探索每个IDC下最优的拥塞控制逻辑。
五、成果与展望
我们不断的优化QUIC链路性能,不断的提升QUIC通道稳定性,旨在为Trip.com日益增长的业务提供优质的网络服务,同时我们也在不断的探索支持更多的QUIC应用场景。
1)通过容器化改造,将扩缩容由手动改为自动,扩缩容时间缩短30倍,在20s内就能拉起并上线大批服务器;
2)通过开发全链路埋点,聚合分析出了较多优化项,修复0-rtt连接问题,连接复用比例提升0.5%,优化拥塞控制算法,端到端耗时缩短4%;
3)通过在FRA(法兰克福)部署QUIC集群,降低了欧洲用户耗时20%以上,提高了网络成功率0.5%以上;
4)支持了携程旅行App和商旅海外App接入QUIC,国内用户和商旅用户在海外场景下网络成功率和性能也大幅提升;
5)客户端升级Cronet之后,综合上述优化项,用户侧端到端整体耗时95线降低18%;
Trip.com在QUIC上的探索将持续的进行,我们将密切关注社区动态,探索支持更多的QUIC应用场景,挖掘更多的优化项目,为携程国际化战略贡献力量。

