韦乐平:大模型时代将开启新一波“光进铜退”的趋势
6月19日,以“智能光网·新场景·新动能”为主题的2024中国光网络研讨会在京举办。
会上,中国电信集团公司科技委主任、中国光网络研讨会大会主席 韦乐平带来《光通信两大热点领域的发展态势及思考》的主题演讲,分享大模型时代光通信发展的新趋势。

▲中国电信集团公司科技委主任、中国光网络研讨会大会主席 韦乐平
T比特时代全面开启
韦乐平指出,“T比特系统技术的基础——T比特oDSP(光数字信号处理器)正逐步走向商用化。”以下是不同波特率级别的oDSP商用化进展的详细概述:
120G波特率级:多家领先的技术供应商,包括Marvell、Acacia、Infinera、Nokia和NEL等,已经推出了基于5nm技术的1.2Tbps oDSP,其120G波特率级的产品均已投入商用。
180G波特率级:Ciena公司则率先在3nm制程上实现了技术突破,推出了1.6Tbps的oDSP,其180G波特率级产品预计在今年实现商用。
240G波特率级:Acacia和Infinera两家公司不仅成功跨越了180G波特率的技术门槛,更是直接推进至240G波特率级。
随着T比特系统技术的快速发展,T比特光模块的商用化进程也在加速。
首先,800G光模块快速崛起,多家技术领先企业已推出基于100G/通道和200G/通道的2/10公里产品陆续进入市场。
同时,面向更长距离的800G/通道的10/20/40/(40-120)/1000公里的产品,也在紧锣密鼓的研发和测试中,预计不久将陆续问世。
在更高速率的探索上,1.6T光模块的研发也在加速进行。据OIF(Optical Internetworking Forum,光互联网论坛)的计划,1.6T ZR/ZR+光模块将在2026年完成标准化工作,并有望在2027年开始商用。
与此同时,T比特传输系统(400/800G)的规模商用也正在逐步展开。在全球范围内,中国的三大运营商正积极引领这一趋势,不仅在大规模部署400G干线网络,还在积极探索800G技术的试验和应用。
目前,分立C6T和L6T光模块已经可用,满足了市场对于高速率、长距离传输的需求。展望未来,预计在2025年,基于铟磷技术的光模块将实现商用,而到了2026年,硅光集成技术有望进一步提升光模块的性能和可靠性。
同样,分立C6T和L6T光纤放大器已经投入市场,为长距离传输提供了可靠的信号放大方案。然而,在长波长噪声因子(NF)方面,仍需要进一步的优化和改进。
依赖于高分辨率LCOS架构等先进技术,C6T+L6T集成式的波长选择开关(WSS)已经在今年陆续开始商用。
在解决信号串扰(SRS)问题、维系波道功率动态均衡等方面,光系统已经取得了显著的进展。
韦乐平指出,“自2026年起,100G资源逐步到达使用寿命,而干线最大链路截面容量高达131T,采用400G扩容可节约15-20%的宝贵光纤资源和大量转发器。”
目前,行业竞争正在加速400G技术的应用进程。2024年,中国移动率先启动400G技术的全面商用,并在性价比方面达到基本可行的水平。
中国电信在400G技术的部署方面有着明确的部署策略。他们计划构建真正的全光交换网络,以WSS为起点实现C+L波段的集成化。
同时,他们还将自研端到端的管控系统和高密度、高速率的CFP2光模块,以进一步提升网络的整体性能和可靠性。
关于800G的技术发展路径,韦乐平将其分为两个阶段。
第一阶段:嵌入式光模块
在2021年,Ciena和Infinera等公司成功实现了短距800G技术的商用化,这一阶段的里程碑主要依赖于7nm制程的ASIC芯片和90G+波特率的oDSP(光学数字信号处理器)。
第二阶段:相干数字可插拔光模块
随着技术的发展和市场需求的提升,800G技术逐步向长距离传输场景拓展,这就需要更高性能的相干数字可插拔光模块。此类模块至少需要5nm和120G波特率级的oDSP,以实现几百公里的传输距离。
若进一步采用2-3nm和240G波特率级的oDSP,并结合拉曼放大等先进技术,则有望将800G技术应用于数百乃至上千公里的普通干线网络。预计在这一阶段,可插拔和嵌入式光模块将并行发展,以满足不同场景下的需求。
800G ZR+(多跨段)技术正在成为业界的关注焦点。其目标是实现多厂家互操作的物理层编解码系统(PCS),相较于400G ZR+,800G ZR+在生态方面更具优势,预计将拥有更大的潜在市场空间。此外,业界也在探讨能否结合G.654.E等新型光纤技术,进一步提升800G技术的传输距离和性能。
180G波特率级路线以3nm、180G波特率级技术为核心,预计将在2024年左右实现商用。Ciena等公司已经在该领域取得了显著的进展,并计划在未来几年内推出相关产品。
240G波特率路线则采用更为先进的2-3nm、240G波特率级技术,Acacia和Infinera等公司正在积极推进该领域的研究和开发。
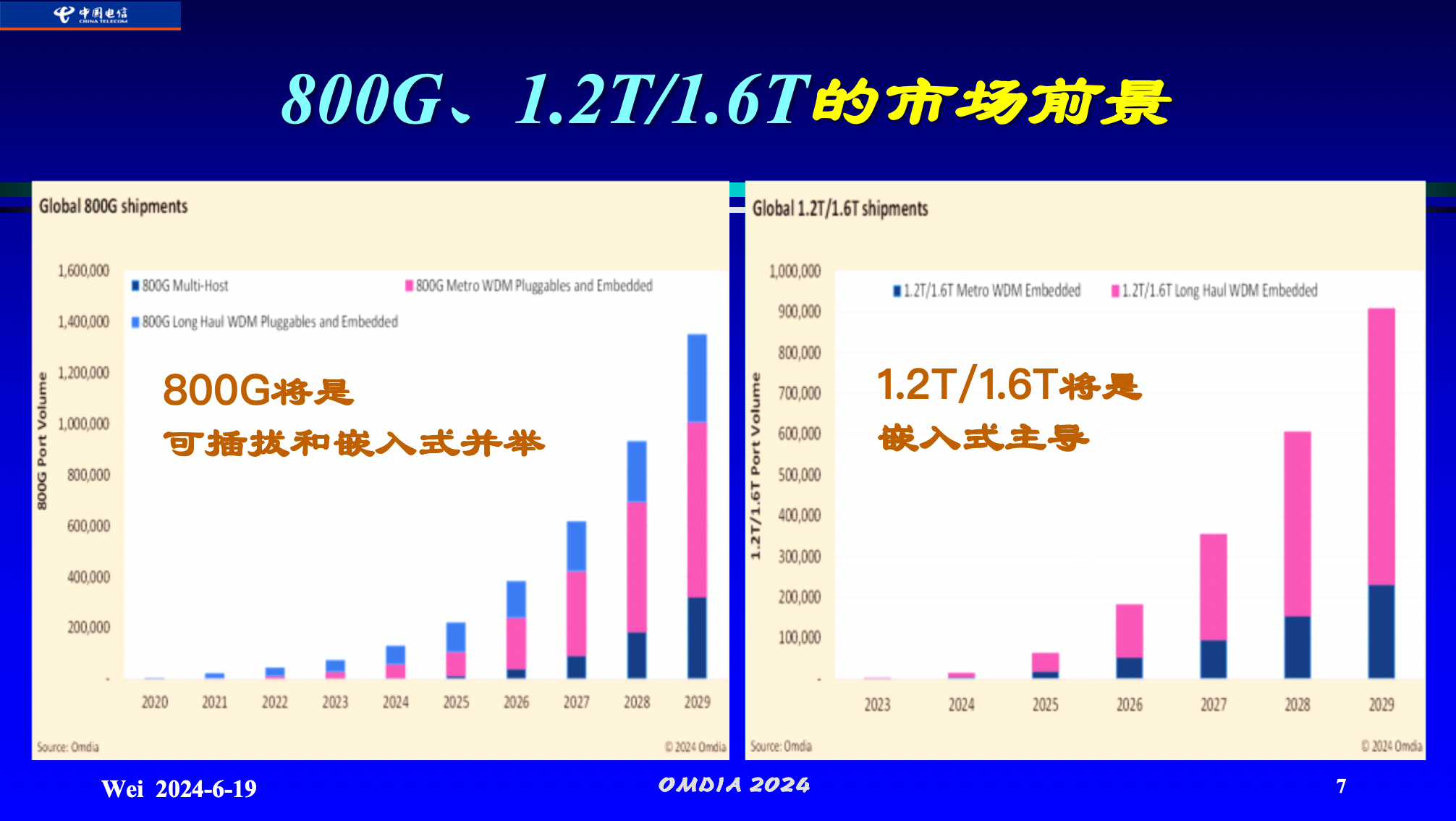
▲800G、1.2T/1.6T的市场前景
关于传送网升级扩容节奏,韦乐平分享了他的思考。
为了规避庞大网络基础设施的频繁升级和简化运营管理,原则上应该继续遵循以4倍速率为基本扩容节奏,这种策略的实施,使每比特的成本降低约30%。
自2012年至今,100G平台已经稳定服务了多年,并预期在未来几年内仍将继续发挥作用。干线传送网的主流大平台通常具有大约15年的服务周期。
从2024年开始,400G作为干线传送网的主流大平台被大规模部署。预计该平台将能够支撑未来10-15年的网络流量需求,其使用寿命至少可延续至2035-2040年。
800G技术的发展速度令人瞩目,预计其将适用于除超长干线传输(如1000公里以上)外的几乎所有网络场景。
根据干线流量增速减缓的现实情况以及技术发展的速度预判,结合400G大平台的15年使用寿命。预测在10-15年后,下一代干线主流大平台的速率将达到1.6T。
数据中心网络以其环境友好、协议简单、业务简单的特点,对技术更新速度有着极高的要求。由于器件寿命相对较短,技术选择多样,且传输距离通常较短,数据中心更注重内连速率、成本和功耗的优化。
尽管光器件和光纤的性能要求不像电信传送网那样严格,但随着大模型对带宽、时延、功耗的不断提升的需求,部分数据中心正逐步向智算中心转型,对于网络和器件的带宽、时延和功耗提出了更高的要求。
关于数据中心光网络升级扩容节奏,韦乐平表示,“鉴于直接面向互联网和人工智能应用的快速发展节奏,因而并不遵循电信传送网的4倍速率扩容原则,而是按需快速扩容。”
每一代光网络平台的技术寿命可能只有数年,这要求数据中心运营商具备快速响应和灵活调整的能力。
考虑到光网络平台扩容的技术路线多样化,其扩容技术路线应随距离、每通道速率、封装等因素的不同而有所差异。例如,短距离内连可能更注重成本和功耗的优化,而长距离传输则可能需要考虑更高的性能和可靠性。
大模型时代光通信发展的新趋势
大语言模型作为人工智能领域的前沿技术,具备大算力、大参数、大数据、大智能等基本特征。
大模型的训练和运行需要庞大的算力支持。算力规模越大、模型参数越多、高质量数据越多,智能就越高,越能解决复杂的任务和推演出更高水平的结果。
行业模型通常拥有百亿至千亿参数,而基础通用大模型则可能达到千亿至万亿参数。全球领先的基础通用大模型,其参数规模更是高达数万亿至数十万亿级。
大模型通常具备一定程度的通用性,即能够完成多领域的诸多任务,而非仅限于单一任务。
当算力、数据和模型参数足够大,训练到一定程度后,大模型会展现出一种神奇的涌现性。这种涌现性能够突然出现预料之外的某种能力,产生逻辑自洽的类人类语言表达,这种能力会达到乃至超过人类某方面的智能。
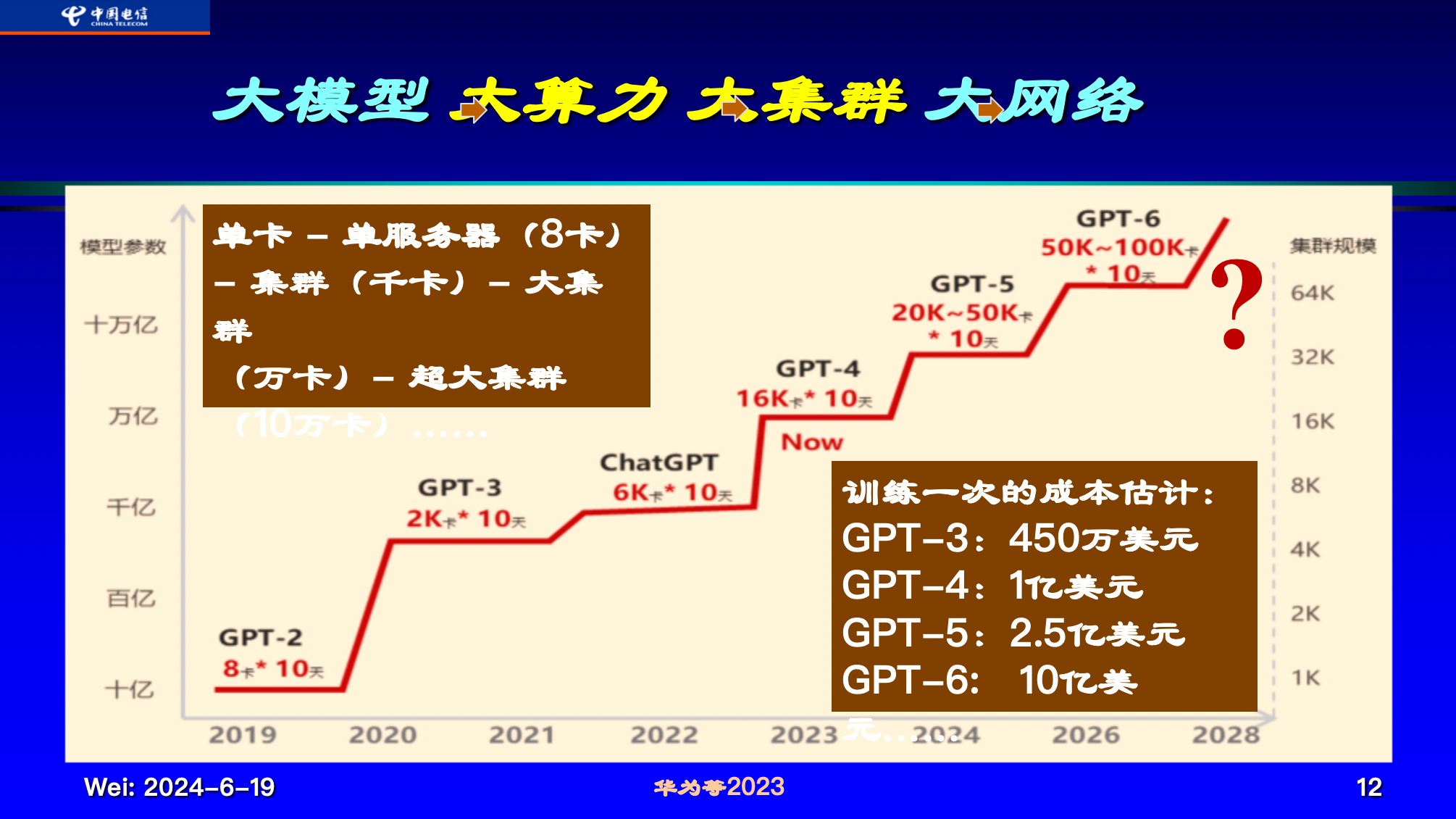
▲大模型 大算力 大集群 大网络
随着大模型的崛起,数据中心(DC)内部交换机光模块的速率、数量和成本正在经历快速的增长。
大模型的训练和推理过程需要巨大的数据传输量和算力支持,这直接推动了数据中心内部高速光模块的需求。以英伟达的GH200系统为例,该系统使用了3072块800Gb/s的光模块,每颗GPU芯片就需要12块800Gb/s的光模块。
Omdia预测,大模型驱动的光模块出货量将从今年的400万涨至1200万,进一步印证了市场对高速光模块的需求正在快速增长。
展望未来3-4年,基于1600ZR/ZR+标准,240-280G波特率的产品将问世。未来10年内,随着技术的不断进步和需求的持续增长,我们有理由相信光模块的技术将不断突破,可能达到400-500G波特率甚至更高的水平。
当前oDSP技术已能采用5nm工艺、120G波特率级、QPSK调制码型,支持400G速率1600公里的超长干线传输。
新一代oDSP技术预期采用3nm工艺、180G或240G波特率级,同样基于QPSK调制码型,应能支持800G速率数百乃至上千公里的普通长距离干线传输。
300G波特率级的oDSP技术已显示出潜力,但400G级别尚无明确的技术路径可寻,表明在进一步提升传输速率上仍存在挑战。
随着技术的演进,模拟电路在oDSP中的功耗占比逐渐增加。在5nm和800G级别,模拟电路消耗了约50%的功率;而在更先进的3nm和预期中的1.6T级别,模拟电路可能消耗高达65%的功率。
因此,将功耗占比较大的模拟电路从oDSP中分离出来,进行单独优化或采用定制化设计,成为降低整体功耗的重要趋势。
随着应用场景的多样化,oDSP技术可能需要根据不同的细分市场进行定制优化。数字副载波调制(DSCM)不仅增强高波特率信号对色散和滤波的容忍度,还能增强对非线性的容忍度,是未来超高速系统趋势之一。
大模型时代将开启新一波“光进铜退”的趋势。
随着基础传输速率攀升至每通道100/200G以上,由于趋肤效应、PCB材料高频损耗、串音干扰等导致PCB板铜箔的损耗和功耗快速上升,减小影响的唯一举措就是减小器件间传输距离,直至完全消除铜连线。
随着传输速率持续提升,光模块的成本也在持续上升。在400G速率,交换机光器件成本的占比已超过50%。在更高速率下,其占比将更高。
为了应对大模型带来的蛮力计算所导致的巨大能耗和成本,“光进铜退”必将从接入网延伸至数据中心乃至服务器、器件或芯片互连直至基本消除电连接。
当然,这一进程不会一蹴而就,随着两者各自的技术进展,博弈将波折前行,但长远大趋势不会逆转。
芯片光互连技术利用CMOS工艺,将光波导、耦合器和谐振器直接刻蚀在硅基上,再利用先进的封装技术将分立的具有特定功能的芯片组(各种XPU)集成进来,构成一个实用化的,结合SiP和Chiplet技术的光互连器。
芯片光互连技术显著提升了计算集群的扩展性,使其能够轻松超越100T的规模,并提供了高达2-4T的带宽,极大地满足了大规模数据处理和传输的需求。
芯片光互连技术的功耗极低,仅为5PJ/Bit,远低于传统互连GPU的可插拔光模块(通常为30PJ/Bit)。芯片光互连技术去掉了带有电I/O接口的传统可插拔光模块的光收发器(transceiver),从而降低了时延、功耗和物理尺寸。
尽管芯片光互连技术具有诸多优势,但其技术尚不成熟,缺乏统一的标准和规范。这可能导致不同厂商的产品之间难以兼容和集成,增加系统设计和部署的复杂性。
在大模型训练时,随着并行计算节点的增多,节点间的通信效率变得尤为重要。网络性能已成为集群算力提升的瓶颈。因此,对于DCN(数据中心网络)而言,高带宽、低时延、低功耗成为关键的技术要求。
随着大模型的崛起,DCN交换机上光模块的数量和速率需求以及成本都在快速增加。以英伟达的GH200超算系统为例,它使用了高达3072块800Gb/s的光模块,这充分说明了大型AI模型对高速率光模块的大量需求。
800GbE光模块正在快速崛起,预计2024年出货量将超过1000万。这一增长主要由用于AI的SR8模块驱动,同时也将影响EML和硅光DR8模块以及2*FR4模块的市场。
另一方面,基于200G/通道的DSP(数字信号处理器)即将商用化,这不仅将催生8通道1.6TbE模块的问世,还将推动4通道800G-DR4模块的成熟。在成本和功率上,4通道800G-DR4模块有望超越传统的8通道800G模块。
随着大模型训练对计算资源需求的增长,单站点的电源、空间等资源将逐渐受限,导致训练范围可能扩展至园区乃至更远的区域。据研究估计,这种外溢将驱动DCI流量增速达35%。
多站点并行训练对时延有极高的要求,这一要求往往决定了集群计算的外溢范围。由于技术限制,这种外溢主要适用于短距离DCI(如园区内)。
目前,绝大多数大模型的训练在单站DCN内即可完成,对DCN内的智算网络的带宽、时延、丢包和可用性都有非常严格的要求。
未来,随着超大规模模型的出现和训练范围的扩展,短距离DCI互联光带宽的需求将增加。这是因为集群计算的范围可能会逐步扩展至园区乃至数十公里更长的距离。
由于时延限制,中短期内对长距离DCI、城域及长途的实质性影响还不明显。这意味着在现有的技术条件下,长距离的数据传输可能仍然面临着较大的挑战。
大模型时代封装技术的机遇和选择,主要围绕光电共封装CPO、线性直驱LPO、线性接收光连接LRO展开。
随着数据传输速率的提升,信号在铜线中的损耗迅速增加。为了维持信号的质量和降低功耗,需要采用新的封装技术。
CPO技术通过将光模块和电交换芯片共封装,能够在高速率下维持最低功耗,满足大模型训练对高效、低耗数据传输的需求。
CPO技术被视为高速率、高密度、低功耗光互连的中长期解决方案。特别是在200Gb/s SerDes及以上速率场景中,CPO技术显示出巨大的潜力。
然而,CPO技术的良率尚不高,维护也不方便,且存在标准滞后的问题。这些挑战正是推动CPO技术不断发展和完善的动力。
LPO技术将光模块内的DSP功能有效地集成到电交换芯片中,这一创新不仅简化了模块结构,而且保持了可热插拔的模块形态。这种设计极大地方便了模块的更换与维护,满足了灵活性和可扩展性的需求。
通过去除DSP芯片,LPO技术显著降低了功耗。由于减少了信号处理的复杂性,LPO技术还实现了更低的时延,这对于需要快速响应的应用至关重要。通过简化模块结构,LPO技术有望降低生产成本,从而提供更具竞争力的市场价格。
面临性能劣化、互操作及更高速率、更长距传输的挑战,LPO技术非常适合100Gb/s SerDes速率的应用场景。
针对LPO技术在性能、功耗和互操作性等方面存在的问题,LRO技术将DSP(数字信号处理器)从电交换芯片移至主机接收端,改进接收灵敏度和误码,还有全套链路诊断功能,功耗也比LPO低很多。
LRO技术的实现难度较低,性能和功耗更佳,是近期传统与LPO间过度方案,可更早地应用于200Gb/s SerDes速率的应用场景。

